Week 21 학습 정리
모델 경량화: 자원 효율성을 높이는 AI 최적화 기술
거대 AI 모델은 수많은 파라미터로 구성되어 있어, 학습 시 많은 GPU, 전력, 시간이 필요합니다. 그러나 대부분의 환경에서는 이러한 자원과 시간을 충분히 확보하기 어렵기 때문에, 모델의 성능을 유지하면서도 크기와 계산 비용을 줄이는 모델 경량화 기술이 중요해졌습니다. 경량화된 모델은 추론 시간도 단축되어 자율주행과 같이 실시간 처리가 요구되는 태스크에 적합합니다.
모델 경량화 주요 기법
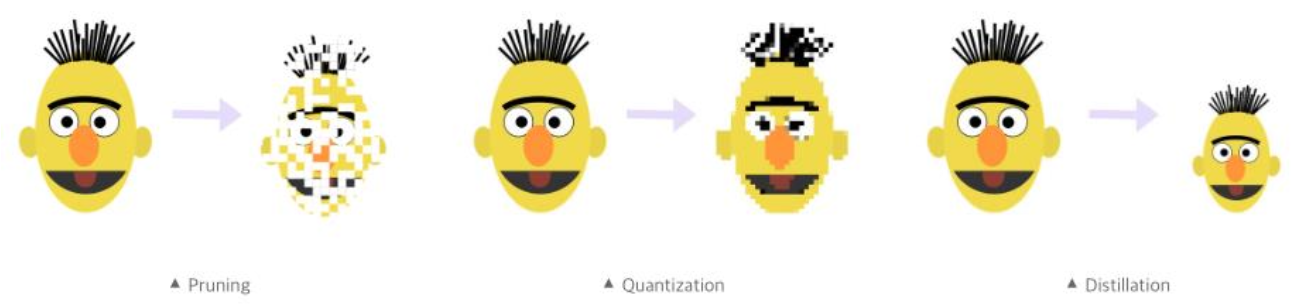
1. Pruning (가지치기)
- 개념:
학습된 모델에서 중요도가 낮은 뉴런이나 연결(시냅스)을 제거하는 방법입니다. - 효과:
모델의 크기와 계산 비용을 줄여 경량화와 속도 향상을 동시에 도모합니다.
2. Knowledge Distillation (지식 증류)
- 개념:
고성능의 Teacher 모델로부터 지식을 전달받아, 더 경량화된 Student 모델을 학습시키는 기법입니다. - 효과:
Teacher 모델의 성능을 최대한 유지하면서, 자원 소모를 줄인 Student 모델을 구축할 수 있습니다.
3. Quantization (양자화)
- 개념:
모델의 가중치와 활성화를 낮은 비트 정밀도로 변환하여 저장 및 계산 효율성을 높이는 방법입니다. - 효과:
연산 속도를 향상시키고 메모리 사용량을 감소시켜, 추론 단계에서 특히 유리한 성능 개선을 이룹니다.
결론
모델 경량화 기술은 자원과 시간이 제한된 환경에서 고성능 AI 모델을 실제 서비스에 적용하기 위한 필수 전략입니다. Pruning, Knowledge Distillation, Quantization과 같은 기법을 통해 모델의 크기를 줄이면서도, 최종 성능은 최대한 유지할 수 있습니다. 이를 통해 실시간 처리가 요구되는 다양한 애플리케이션, 예를 들어 자율주행, 모바일 애플리케이션 등에 효과적으로 활용할 수 있습니다.
모델 경량화를 위한 Pruning 기술
거대 AI 모델은 수많은 파라미터로 이루어져 있어 메모리 사용량과 연산 비용이 큽니다. 이를 줄이기 위해 중요도가 낮은 뉴런이나 연결(시냅스)을 제거하는 pruning 기법이 사용됩니다. Pruning을 통해 모델의 크기를 줄이고, 계산 속도를 높이며, 추론 시간도 단축할 수 있습니다.
Pruning 기법은 크게 구조(structure), 스코어링(scoring), 스케줄링(scheduling), 초기화(initialization) 네 가지 관점에서 접근할 수 있습니다.
1. Pruning 기법의 분류
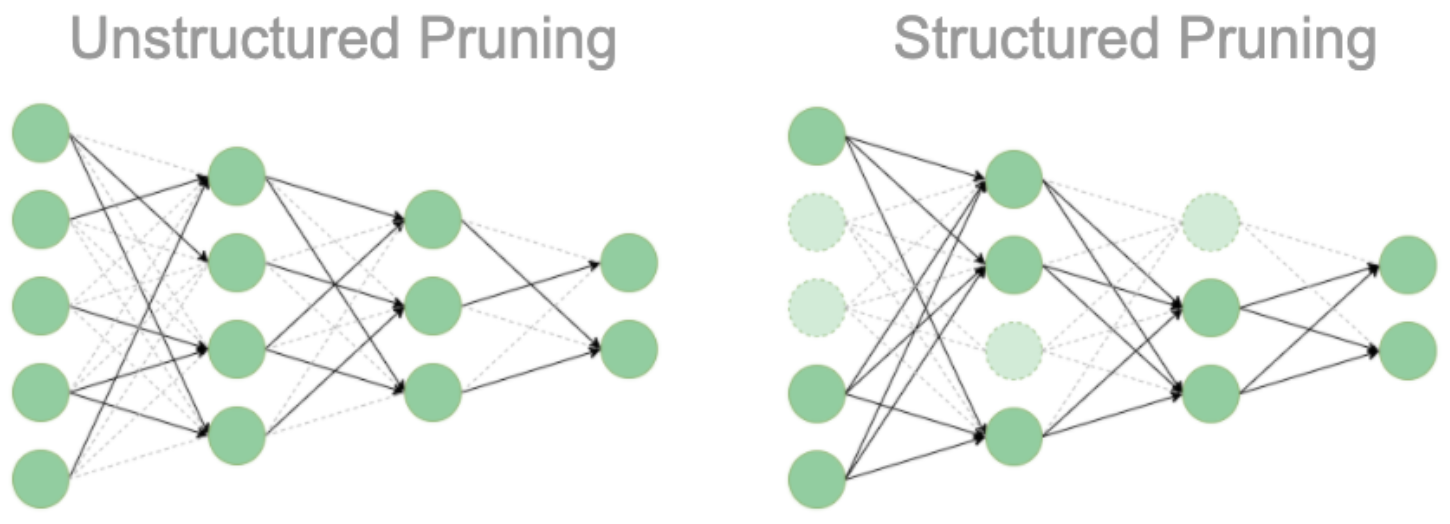
1-1. Structure: 모델 구조 변화 여부
-
Unstructured Pruning
개별 파라미터 단위로 중요도가 낮은 값을 0으로 변경하여 제거합니다.- 장점: 구현이 상대적으로 쉽습니다.
- 단점: 모델 구조 자체는 변하지 않으므로, 0으로 채워진 부분을 그대로 연산에 사용하게 되어 연산 속도 향상은 미미할 수 있습니다.
-
Structured Pruning
뉴런, 채널, 혹은 레이어 전체를 제거하여 모델의 구조를 변경합니다.- 장점: 구조 변경으로 인해 실제 연산 속도 향상을 기대할 수 있습니다.
- 단점: 구현이 복잡하거나 경우에 따라 불가능할 수도 있습니다.
| 방법 | 단위 | 구조 변경 여부 | 장점 | 단점 |
|---|---|---|---|---|
| Unstructured | 개별 파라미터 | 없음 | 구현이 쉬움 | 연산 속도 향상 미흡 |
| Structured | 뉴런/채널/레이어 | 있음 | 연산 속도 향상 가능 | 구현이 어렵거나 제한적일 수 있음 |
1-2. Scoring: 가지치기할 파라미터 선정
중요도 계산 방법
- 개별 파라미터 기준: 각 파라미터의 절댓값을 기준으로 중요도를 평가하여, 절댓값이 작은 파라미터를 제거합니다.
- 레이어 별 Lp-norm 기준: 레이어마다
(예: )을 계산해, 해당 값이 작은 레이어의 파라미터를 제거합니다.
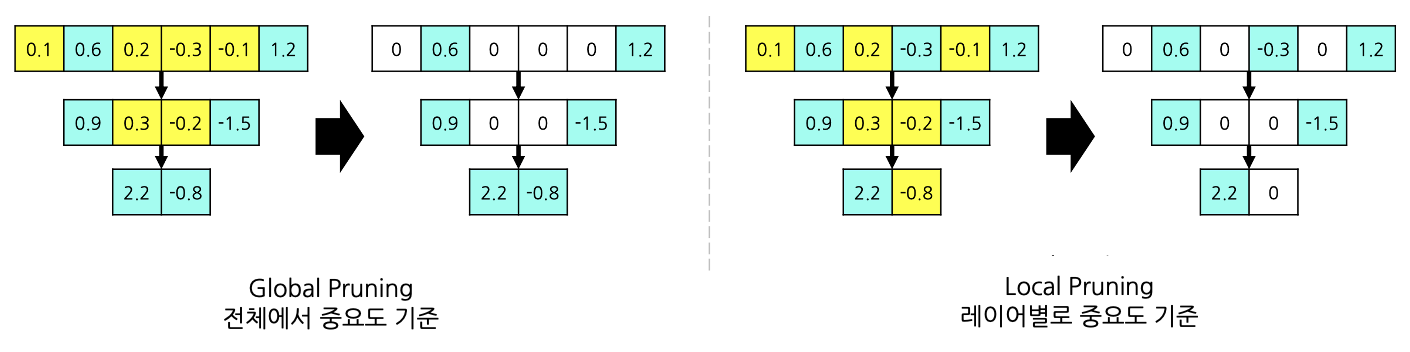
중요도를 반영하는 단위
- Global Pruning:
전체 모델에서 중요도가 낮은 파라미터를 선택해 제거합니다.- 장점: 중요한 레이어의 파라미터는 상대적으로 보존됩니다.
- 단점: 계산량이 많아질 수 있습니다.
- Local Pruning:
각 레이어별로 중요도 하위 일정 비율(예: 하위 50%)의 파라미터를 제거합니다.- 장점: 특정 레이어에 과도하게 집중되지 않아 균형 있게 가지치기할 수 있습니다.
- 단점: 중요한 레이어에서 불필요하게 많은 파라미터가 제거될 위험이 있습니다.
1-3. Scheduling: 가지치기 진행 방식
- One-shot Pruning:
한 번에 가지치기를 수행합니다. 빠르지만 성능이 불안정할 수 있습니다. - Recursive (Iterative) Pruning:
여러 번에 걸쳐 조금씩 가지치기를 진행합니다. 시간이 오래 걸리지만 성능 안정성이 높습니다.
1-4. Initialization: Fine-tuning 시작점
가지치기 후 모델을 재학습할 때, 초기 상태에 따라 두 가지 방식이 있습니다.
- Weight-Preserving (Classic):
가지치기 직후의 모델 상태에서 바로 fine-tuning을 진행합니다. 학습과 수렴이 빠르지만 성능이 불안정할 수 있습니다. - Weight-Reinitializing (Rewinding):
가지치기 후 모델의 일부를 랜덤 값으로 초기화한 후 fine-tuning을 진행합니다. 학습 시간이 더 걸리지만, 성능 안정성이 향상될 수 있습니다.
Iterative Magnitude Pruning (IMP):
가장 기본적인 pruning 방법으로,
- unstructured 방식,
- global (파라미터별 절대값 기반),
- recursive (iterative) 방식,
- rewinding을 결합하여 수행합니다.
2. 추가 고려 사항
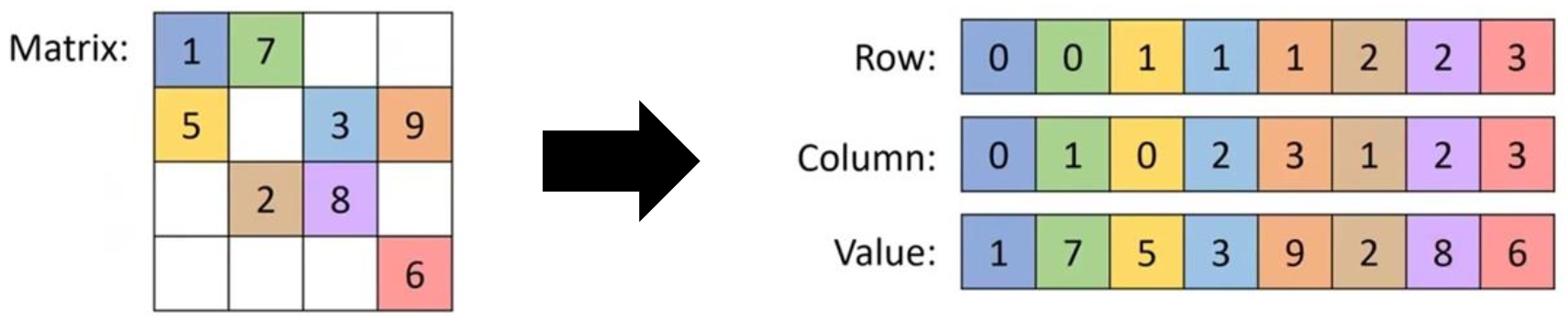
2-1. Matrix Sparsity 문제
-
정의:
matrix의 대부분 요소가 0인 상태를 의미합니다.-
Density:
density=0이 아닌 요소의 개수전체 요소의 개수\text{density} = \frac{\text{0이 아닌 요소의 개수}}{\text{전체 요소의 개수}}
-
Sparsity:
sparsity=0인 요소의 개수전체 요소의 개수=1−density\text{sparsity} = \frac{\text{0인 요소의 개수}}{\text{전체 요소의 개수}} = 1 - \text
-
-
문제점:
Unstructured pruning으로 생성된 0 값이 여전히 연산에 포함되면, 계산 속도 향상이 미흡할 수 있습니다. -
해결 방안:
- Sparse Matrix Representation:
0이 아닌 요소들의 좌표를 저장하여 연산 시 활용 (sparsity가 매우 높은 경우). - 전용 하드웨어:
NVIDIA Tensor Core와 같이, sparse 연산을 최적화한 하드웨어를 사용합니다.
- Sparse Matrix Representation:
2-2. Sensitivity (민감도)
- 개념:
가지치기한 파라미터나 레이어가 모델 전체 성능에 미치는 영향을 평가하는 지표입니다. - 실무:
일반적으로 앞쪽 레이어가 민감도가 높고, 뒤쪽 레이어가 덜 민감한 경향이 있습니다. 이를 기반으로 empirical하게 pruning 비율을 결정합니다.
3. In Practice: CNN과 BERT에서의 Pruning
3-1. CNN에서의 Pruning
- CNN 구성:
보통 Convolutional Layer와 Fully-Connected Layer(FC)로 구성됩니다. - 특징:
- 대부분의 파라미터는 FC layer에 집중되어 있지만, 연산 속도 병목은 CNN 레이어에서 발생합니다.
- 효율적인 pruning을 위해 CNN의 필터(커널)와 FC layer 모두를 대상으로 가지치기를 수행합니다.
- 방법:
CNN 레이어에서는 중요도가 낮은 필터를 제거하며, 중요도는 주로 sparsity 또는 L₂-norm 값 기준으로 판단합니다.
3-2. BERT에서의 Pruning
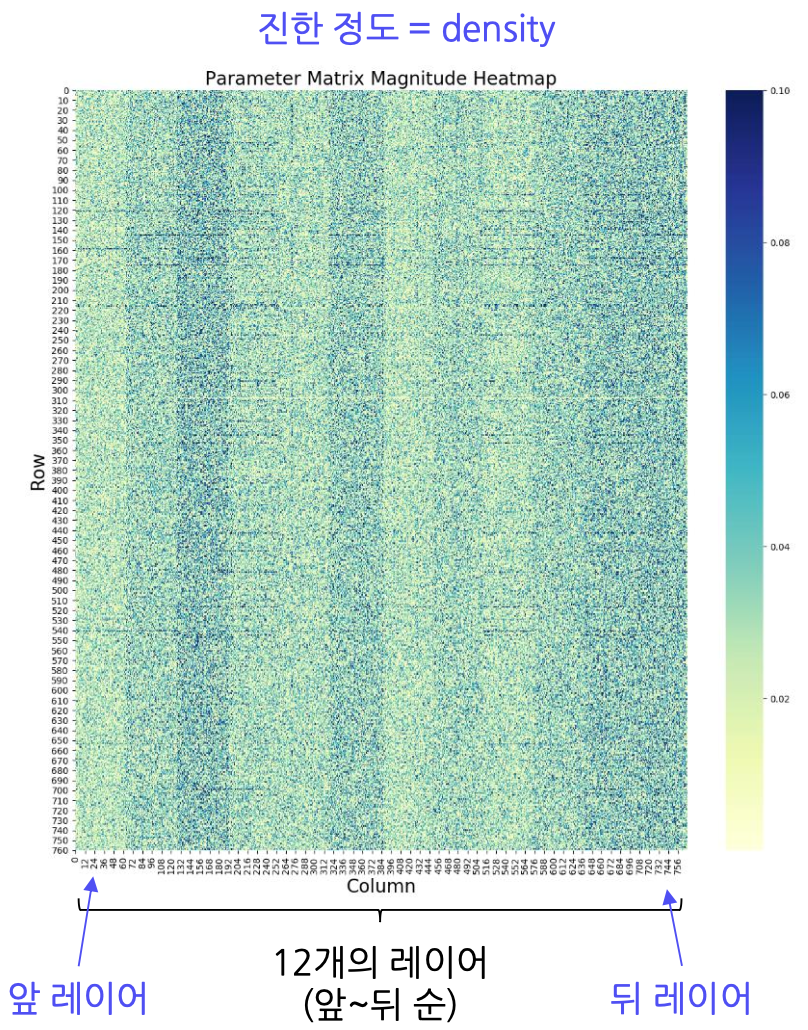
- BERT 구성:
12개의 Transformer 레이어로 이루어진 다용도 언어 모델입니다. - 특징:
- BERT는 앞쪽 레이어에서 단어 단위의 작은 정보를, 뒤쪽 레이어에서 문장과 같은 큰 정보를 처리합니다.
- 레이어별 sparsity가 일정하지 않아, global 또는 structured pruning 시 성능 저하 위험이 있습니다.
- 절댓값 기반의 pruning이 효과적이며, 앞쪽 레이어에 대해서는 local pruning을 적용해 성능 저하를 최소화할 수 있습니다.
4. 예제 코드 (PyTorch 기반)
다음은 간단한 2-layer MLP 모델에 대해 unstructured pruning을 적용하는 예제입니다.
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
# 2-layer MLP 모델 정의
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(2, 10)
self.fc2 = nn.Linear(10, 2)
def forward(self, x):
x = self.fc1(x)
x = torch.relu(x)
x = self.fc2(x)
return x
# 모델 선언 및 학습/테스트 함수 정의 (train, test는 별도 구현)
model = Model()
# 학습 및 테스트 (pruning 전)
train(model, train_data)
test(model, test_data)
# 전체 파라미터 수 확인
total_params = sum(p.numel() for p in model.parameters())
total_params_nz = sum((p != 0.0).sum().item() for p in model.parameters())
print("전체 파라미터:", total_params)
print("0이 아닌 파라미터:", total_params_nz)
# Pruning 대상 레이어 선택 (예: 첫 번째 Fully Connected 레이어)
layer = model.fc1
# 1) 랜덤으로 첫 번째 레이어에서 50%를 제거 (unstructured)
prune.random_unstructured(layer, name='weight', amount=0.5)
# 2) 파라미터 절댓값 기준 하위 50%를 제거 (L1-based pruning)
prune.l1_unstructured(layer, name='weight', amount=0.5)
# pruning 후 fine-tuning을 위해 다시 학습
train(model, train_data)
# pruning 및 fine-tuning 후 테스트
test(model, test_data)
설명:
- 먼저 모델을 학습 및 테스트한 후, 첫 번째 레이어의 weight tensor에 대해 unstructured pruning을 적용합니다.
prune.random_unstructured는 무작위로 50%의 파라미터를 0으로 만듭니다.prune.l1_unstructured는 각 파라미터의 절댓값을 기준으로 하위 50%를 0으로 만듭니다.- 이후 fine-tuning을 통해 pruning으로 인한 성능 저하를 보완합니다.
결론
Pruning은 모델 경량화의 핵심 기법 중 하나로,
- 구조적인 접근(structure): unstructured와 structured 방식 선택
- 스코어링(scoring): 파라미터 중요도 평가 방법 (절댓값, Lp-norm) 및 global vs. local 방식
- 스케줄링(scheduling): 한 번 혹은 여러 번의 iterative 방식
- 초기화(initialization): fine-tuning 시 weight-preserving 또는 reinitializing 선택
추가로, matrix sparsity, 전용 하드웨어 활용, 그리고 각 레이어의 sensitivity 등을 고려하여 최적의 pruning 전략을 설계할 수 있습니다. CNN이나 BERT와 같은 모델에 pruning을 적용하는 실제 사례를 통해, 모델의 크기와 연산 비용을 효과적으로 줄이면서도 성능을 유지할 수 있음을 확인할 수 있습니다.
Knowledge Distillation (지식 증류)
Knowledge Distillation(KD)은 고성능의 Teacher 모델로부터 지식을 전달받아, 상대적으로 경량화된 Student 모델을 학습시키는 기법입니다.
Teacher 모델은 파라미터 수가 많아 성능은 좋지만 연산 비용과 추론 속도가 느린 반면, Student 모델은 파라미터 수가 적어 빠른 추론 속도를 자랑합니다. KD를 통해 성능은 최대한 유지하면서도 모델 경량화와 연산 효율성을 높일 수 있습니다.
1. KD 기법의 분류
1-1. Knowledge 관점
Response-based KD
- Logit-based KD:
Teacher 모델의 logit 값(즉, 출력 확률 분포)을 Student 모델이 모방하도록 학습합니다.- 방법:
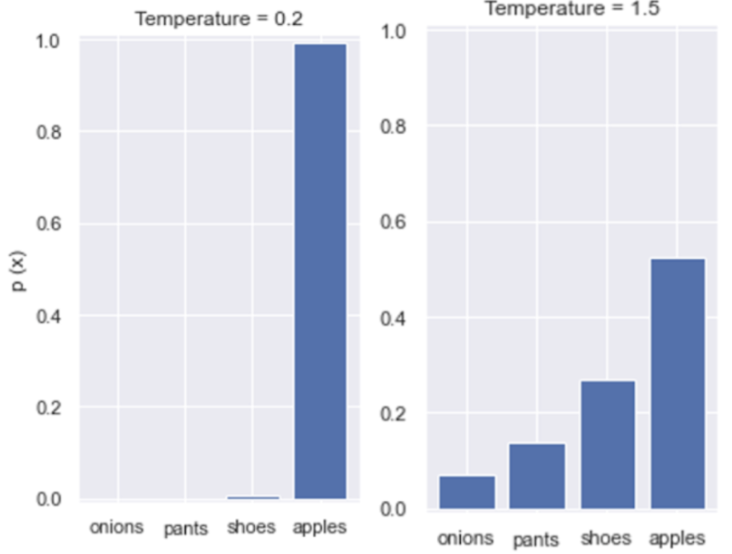
Teacher가 예측한 클래스 확률 분포(예: cat=0.8, cow=0.07, dog=0.13)를 Student가 예측하도록 KL divergence를 loss로 사용합니다. - Temperature T:
- T < 1: 확률 분포가 더 날카롭게(높은 contrast)
- T > 1: 확률 분포가 완만하게(낮은 contrast)
적절한 T 값 설정은 증류 성능에 큰 영향을 미칩니다.
- 방법:
Feature-based KD
- Teacher 모델의 중간 레이어에서 추출한 feature 또는 표현(representation)을 Student 모델이 모방하도록 합니다.
- 보통 Teacher와 Student의 중간 레이어 차원이 다르기 때문에, Student 모델에는 regressor layer(또는 projection layer)를 추가하여 차원을 맞추고, 두 feature map 간의 차이를 MSE loss 등으로 줄입니다.
1-2. Transparency 관점
- White-box KD:
Teacher 모델의 내부 구조와 파라미터 등을 완전히 열람할 수 있는 경우. - Gray-box KD:
Teacher 모델의 output 및 최종 logit 값 등 제한된 정보만 열람 가능한 경우. - Black-box KD (Imitation Learning):
Teacher 모델의 내부 구조나 파라미터는 알 수 없고, 입력에 따른 결과만을 바탕으로 Student 모델이 모방 학습하는 방식.- 장점: 데이터 수집 비용이 낮고, 인간이 해석 가능한 형태의 지식을 전달받을 수 있습니다.
- 단점: Teacher가 오류가 있는 예측을 한다면 그 영향을 그대로 받을 위험이 있습니다.
2. KD 적용 단계
- 모방 데이터 수집:
Teacher 모델에 특정 질문(seed 질문)을 입력하여 응답 데이터를 수집합니다.- 예: "반품 정책은 어떻게 되나요?" → "반품 절차가 몇 단계로 이루어져 있는지 각 단계별로 자세히 설명해주세요."
- 데이터 전처리:
수집된 데이터에서 불필요하거나 노이즈가 많은 부분(의미 없는 대화, 지나치게 짧은 답변, hallucination 등)을 제거하고, 질문-답변의 균형을 맞춥니다. - Student 모델 학습:
전처리된 데이터를 이용해 Student 모델을 학습시킵니다.
3. Logit-based KD 예제 (PyTorch 코드)
아래는 Teacher 모델과 Student 모델을 정의하고, Teacher의 지식을 기반으로 Student 모델을 학습시키는 간단한 예제 코드입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
# Teacher 모델 정의 (예시)
class Teacher(nn.Module):
def __init__(self, num_classes=10):
super(Teacher, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, num_classes)
def forward(self, x):
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
return self.fc2(x) # Logits 출력
teacher = Teacher(num_classes=10)
print("Teacher 파라미터 수:", sum(p.numel() for p in teacher.parameters()))
# Student 모델 정의 (더 얕은 네트워크)
class Student(nn.Module):
def __init__(self, num_classes=10):
super(Student, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, num_classes)
def forward(self, x):
x = x.view(x.size(0), -1)
x = F.relu(self.fc1(x))
return self.fc2(x)
student = Student(num_classes=10)
print("Student 파라미터 수:", sum(p.numel() for p in student.parameters()))
# Teacher 모델 학습 (일반적인 Cross-Entropy Loss 사용)
def train_teacher(model, train_data, optimizer, epochs=10):
model.train()
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
for x, y in train_data:
optimizer.zero_grad()
logits = model(x)
loss = criterion(logits, y)
loss.backward()
optimizer.step()
# Teacher 모델 평가
def test_model(model, test_data):
model.eval()
total, correct = 0, 0
with torch.no_grad():
for x, y in test_data:
logits = model(x)
preds = logits.argmax(dim=1)
total += y.size(0)
correct += (preds == y).sum().item()
print("Accuracy: {:.2f}%".format(100 * correct / total))
# Teacher 모델 학습 및 평가
optimizer_teacher = torch.optim.Adam(teacher.parameters(), lr=1e-3)
train_teacher(teacher, train_data, optimizer_teacher, epochs=10)
test_model(teacher, test_data)
# Student 모델 학습 (Hard label + Soft label with KD)
def train_student(teacher, student, train_data, optimizer, epochs=10, T=2.0, alpha=0.5):
teacher.eval() # Teacher는 고정
criterion = nn.CrossEntropyLoss()
kl_loss_fn = nn.KLDivLoss(reduction='batchmean')
student.train()
for epoch in range(epochs):
for x, y in train_data:
optimizer.zero_grad()
# Teacher 예측 (soft target)
with torch.no_grad():
teacher_logits = teacher(x)
soft_target = F.log_softmax(teacher_logits / T, dim=1)
# Student 예측
student_logits = student(x)
# Hard label loss (Cross-Entropy)
loss_hard = criterion(student_logits, y)
# Soft label loss (KL divergence)
loss_soft = kl_loss_fn(F.log_softmax(student_logits / T, dim=1), soft_target)
# Total loss: alpha 조합
loss = alpha * loss_hard + (1 - alpha) * (T * T) * loss_soft
loss.backward()
optimizer.step()
# Student 모델 평가
optimizer_student = torch.optim.Adam(student.parameters(), lr=1e-3)
train_student(teacher, student, train_data, optimizer_student, epochs=10, T=2.0, alpha=0.5)
test_model(student, test_data)
설명:
- Teacher 모델은 더 큰 네트워크로, Cross-Entropy Loss를 사용해 학습됩니다.
- Student 모델은 Teacher보다 작은 네트워크로, 학습 시 hard label (원래 정답)과 soft label (Teacher의 logit 분포)을 모두 사용합니다.
- Temperature TT와 혼합 계수 alphaalpha를 통해 두 loss 간의 가중치를 조절합니다.
결론
Knowledge Distillation은 고성능 Teacher 모델의 정보를 효과적으로 압축하여, 경량화된 Student 모델을 학습시키는 기법입니다.
- Response-based KD (Logit-based KD): Teacher의 출력 확률 분포를 Student가 모방하도록 하여, 클래스 간의 유사도 정보를 함께 학습합니다.
- Feature-based KD: 중간 레이어의 feature를 모방하는 방법으로, 보통 regressor를 통해 차원 조정 후 MSE loss를 사용합니다.
- Transparency 관점: Teacher 모델의 내부 구조를 얼마나 열람할 수 있는지에 따라 white-box, gray-box, black-box KD로 구분할 수 있습니다.
모델 경량화를 위한 Quantization(양자화) 기법 이해하기
거대 AI 모델은 고정밀 FP32 형식의 가중치와 활성화를 사용하기 때문에 메모리 사용량과 연산 비용이 매우 큽니다. Quantization(양자화)은 이러한 모델의 가중치와 활성화를 낮은 비트 정밀도로 변환하여 저장 및 계산 효율성을 높이는 기법입니다. 예를 들어, π를 3.141592처럼 고정밀하게 표현하면 메모리 사용량이 크지만, 3과 같이 낮은 정밀도로 표현하면 메모리 사용은 줄어들지만 오차가 발생할 수 있습니다. Quantization의 핵심은 오차를 최소화하면서도 효율적인 낮은 정밀도를 찾는 것입니다.
Quantization Mapping
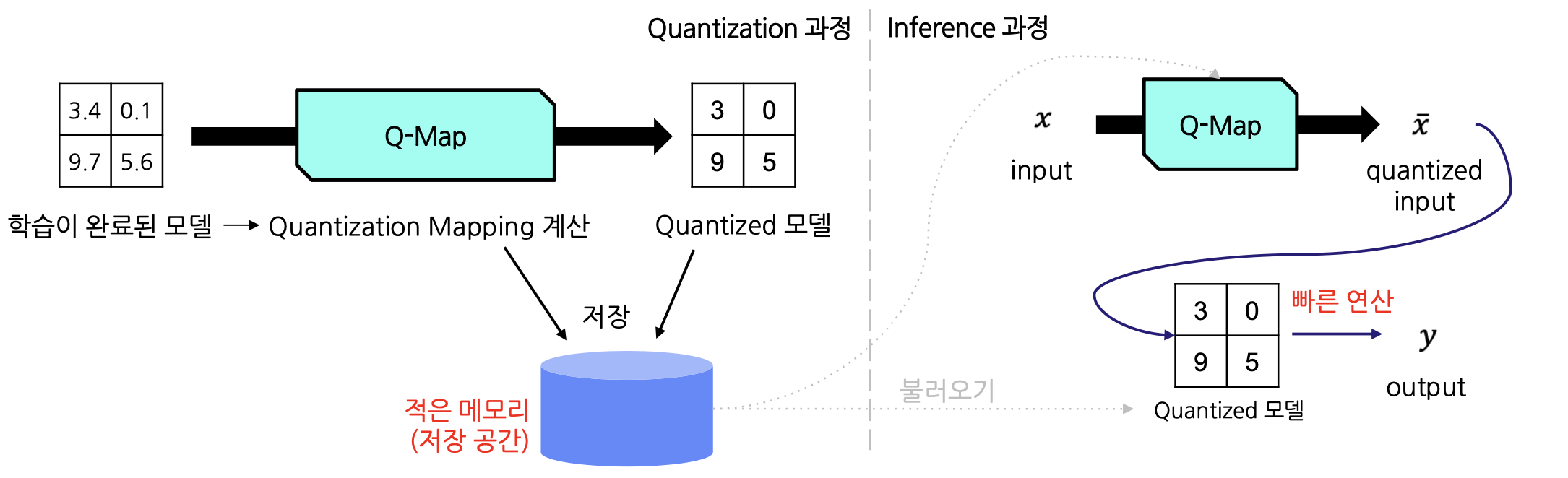
Quantization은 높은 정밀도의 값을 낮은 비트 정밀도의 값에 매핑하는 과정을 포함합니다. 일반적으로 모델의 데이터나 파라미터는 FP32 형식으로 표현되는데, 이를 FP16, INT8 등으로 변환합니다. 다만, 각 자료형마다 표현 가능한 값의 범위가 다릅니다.
| 타입 | 표현 가능 최소 | 표현 가능 최대 |
|---|---|---|
| INT8 | -128 | 127 |
| INT16 | -32768 | 32767 |
| INT32 | -2147483648 | 2147483647 |
| FP16 | -65504 | 65504 |
| FP32 | -3.4028235 × 10^38 | 3.4028235 × 10^38 |
예를 들어, FP32로 표현된 350.5는 INT8의 최대 표현 범위(127)를 초과하기 때문에 직접적인 변환이 불가능합니다.
Quantization Mapping은 보통 아래와 같은 수식을 사용하여 진행됩니다.
: 원본 값 : 양자화된 값 : scale factor (기울기) : zero-point (양자화 후 0이 매핑되는 위치)
양자화 시, 이
Quantization 기법의 종류
1. Absmax Quantization
-
개념:
데이터 분포의 절댓값 최대치에 기반해 scale factor를 결정합니다.이 방식에서는
로 고정됩니다. -
적용:
데이터 분포가 대칭적이거나 평균이 0인 경우(예: tanh 함수의 출력)에 효과적입니다. -
단점:
극단적인 값(Outlier)에 민감하여, 이러한 값들이 scale factor에 큰 영향을 줄 수 있습니다.
2. Zero-point Quantization
-
개념:
데이터 분포가 비대칭적이거나 평균이 0이 아닌 경우에 사용합니다.
전체 범위가 일정하게 매핑되도록 scale factor와 zero-point를 계산합니다.
-
적용:
주로 ReLU와 같이 출력이 0 이상인 경우에 유리합니다. -
단점:
기준점(z)이 비정상적으로 설정되면 성능 저하로 이어질 수 있습니다.
Clipping과 Calibration
데이터에 outlier가 존재하면, 양자화 mapping이 효과적이지 않을 수 있습니다. 이를 해결하기 위해 clipping 기법을 사용합니다. 예를 들어, 데이터 값의 범주를 [−5,5][-5, 5]로 제한하고, 이 범위를 넘어서는 값은 모두 같은 값으로 취급합니다. 이 과정에서 적절한 범주를 선택하는 것을 calibration이라고 합니다.
결론
Quantization은 모델의 가중치와 활성화를 낮은 비트 정밀도로 변환하여 메모리 사용량을 줄이고 연산 효율성을 높이는 중요한 모델 경량화 기법입니다.
- Absmax Quantization은 데이터 분포가 대칭적일 때 유리하며,
- Zero-point Quantization은 비대칭적인 분포에 효과적입니다.
또한, clipping과 calibration을 통해 outlier의 영향을 최소화하는 것이 중요합니다.
Parameter-Efficient Fine-Tuning (PEFT): 거대 모델의 효율적 미세조정
거대 AI 모델의 학습은 수많은 파라미터로 인해 막대한 자원과 시간이 소요됩니다. 이러한 상황에서 전체 모델을 재학습하는 대신, 모델의 일부분만 미세조정하여 효율성을 극대화하는 Parameter-Efficient Fine-Tuning (PEFT) 기법이 주목받고 있습니다. PEFT는 전이 학습(Transfer Learning)의 Fine-tuning 단계에서 전체 파라미터를 업데이트하지 않고, 일부 파라미터만 학습시켜 빠르고 비용 효율적인 모델 개선을 목표로 합니다.
1. 전이 학습과 PEFT
- 전이 학습(Transfer Learning):
이미 학습된 모델(Pre-trained Model)을 새로운 작업의 시작점으로 활용하는 방법으로,- Pre-training: 방대한 양의 데이터로 모델을 사전 학습
- Fine-tuning: 특정 작업에 맞춰 모델을 재학습
- Fine-tuning의 필요성:
사전 학습 모델은 일반적인 문제 해결 능력이 부족하기 때문에, 새로운 태스크에 맞춰 재학습하는 과정이 필요합니다.
PEFT는 Fine-tuning 시 전체 모델을 업데이트하지 않고 일부 파라미터만 학습하여 효율성을 높이는 접근법입니다.
2. PEFT의 접근 방식
PEFT는 크게 두 가지 방법론으로 나눌 수 있습니다.
2-1. Prompt Tuning 방식
- 개념:
모델의 기존 파라미터를 변경하지 않고, 입력 prompt나 context를 조정하여 원하는 출력으로 유도합니다. - 예시:
Prompt Tuning, Prefix Tuning, P-Tuning 등
2-2. 파라미터 삽입 방식
- 개념:
모델의 특정 위치에 추가 학습 가능한 파라미터(모듈)를 삽입하여 미세조정합니다. - 예시:
Adapter, LoRA, Compacter 등
3. 파라미터 삽입 방식 상세
3-1. Adapter
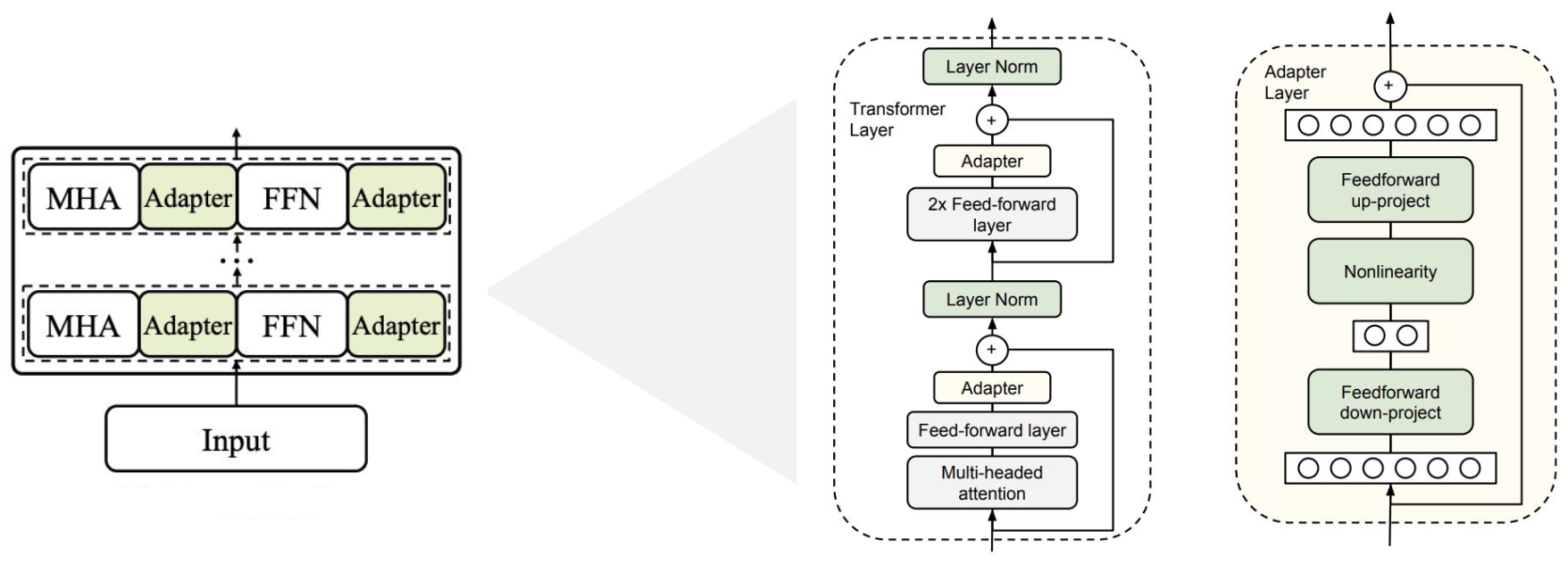
- 구조:
- 기존 모델의 각 레이어 사이에 작은 adapter 모듈을 삽입
- Bottleneck 구조: 먼저 다운-프로젝션(차원 축소) → 비선형 활성화 → 업-프로젝션(원래 차원 복원)
- Skip-connection을 통해 원래 입력을 복원 후 합산
- 특징:
기존 파라미터는 그대로 두고 adapter만 학습하여 태스크에 맞게 모델을 빠르게 전환할 수 있습니다.
3-2. Low-Rank Decomposition
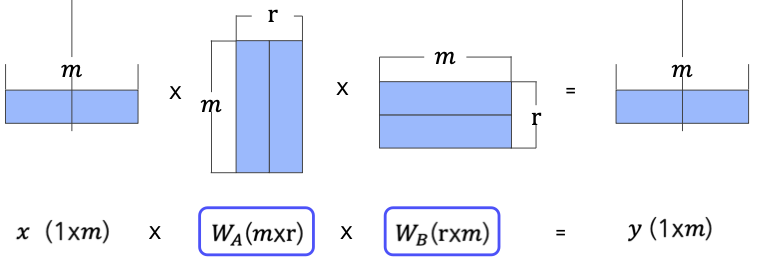
- 개념:
고차원 weight matrix를 두 개의 저차원 행렬(예: m×rm \times r와 r×mr \times m, r<mr < m)의 곱으로 근사하여 파라미터 수를 줄이는 방법 - 적용:
예를 들어, 300×300300 \times 300 행렬을 300×10300 \times 10와 10×30010 \times 300 행렬로 분해하여 경량화
3-3. LoRA (Low-Rank Adaptation)
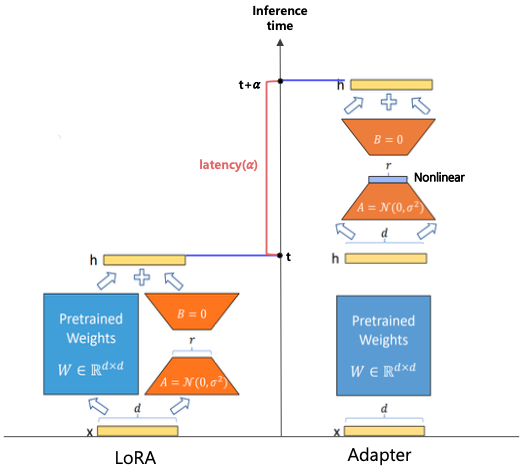
- 개념:
사전 학습된 모델 가중치는 고정한 채, 각 층에 low-rank 분해된 추가 파라미터를 병렬적으로 삽입하여 학습합니다. - 특징 비교 (Adapter vs. LoRA):
| 항목 | Adapter | LoRA |
|---|---|---|
| 연산 방식 | Sequential (순차적) | Parallel (병렬적) |
| 비선형 함수 사용 여부 | 사용함 | 사용하지 않음 |
| 학습 파라미터 | Weight 및 bias | Weight만 |
| 연산 지연 | 모듈 연산에 비례 | 거의 발생하지 않음 |
LoRA는 Adapter와 유사한 low-rank 기법을 사용하지만, 병렬적으로 계산하여 속도 측면에서 더 효율적입니다.
3-4. AdapterFusion
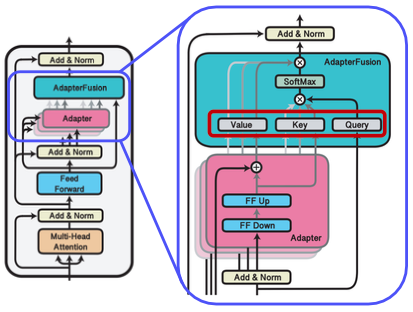
- 개념:
여러 태스크에 대해 각각 학습한 adapter 모듈들을 결합하여 하나의 모델로 구성하는 방법입니다. - 동작 방식:
- Knowledge Extraction: 각 태스크별로 개별 adapter를 학습
- Knowledge Composition: 입력에 따라 여러 adapter의 출력을 attention 기반으로 취합하여 최적의 결과를 생성
- 장점:
단일 모델로 다양한 태스크를 빠르게 전환할 수 있으며, adapter 모듈만 변경하면 되므로 효율적입니다.
3-5. QLoRA
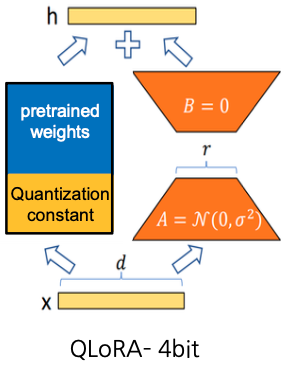
- 개념:
LoRA에 Quantization 기법을 추가 적용하여, 메모리와 연산 효율성을 극대화한 방법입니다. - 방법:
- 사전 학습 모델 가중치를 16-bit에서 4-bit Normal-Float Quantization으로 변환
- 양자화 상수(Scale과 Zero-point)는 높은 정밀도로 저장하여, double quantization을 수행
4. In Practice: LoRA 적용 사례
예를 들어, BERT_base 모델에 LoRA를 적용하여 SQuAD 데이터셋을 사용한 경우를 살펴보겠습니다.
# 기존 모델 파라미터 고정 (Fine-tuning 시 고정)
for param in model.parameters():
param.requires_grad = False
# LoRA 설정 (예시)
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(
r=2, # Low-rank factor (예: 1-4 정도 사용)
lora_alpha=16, # Low-rank matrix에 곱해지는 값으로, 수렴을 돕습니다.
target_modules=["query", "value"], # 적용할 모듈 지정
lora_dropout=0.1 # Dropout으로 과적합 방지
)
# PEFT 모델 생성
model_with_lora = get_peft_model(model, lora_config)
- 설명:
- 기존 BERT_base 모델의 파라미터는 고정하고, 특정 모듈(query, value)에 대해서만 low-rank 학습 가능한 파라미터를 삽입합니다.
- LoRA 설정에 따라, 추가되는 파라미터는 훨씬 작으면서도 충분한 성능을 유지할 수 있습니다.
결론
PEFT 기법은 거대 모델의 전체 재학습 없이도, 모델의 일부만 미세조정하여 학습 비용과 시간을 크게 줄일 수 있는 효율적인 방법입니다.
- Prompt Tuning은 입력만 조정하는 방법이며,
- 파라미터 삽입 방식은 Adapter, LoRA, AdapterFusion, QLoRA 등 다양한 기법으로 구분됩니다.