Week 7-8 학습 정리
이미지 데이터의 이해와 전처리, 분류 기법
AI와 컴퓨터 비전 분야에서 이미지 데이터는 핵심 자원입니다.
이미지 데이터는 단순히 픽셀들의 집합일 뿐만 아니라, 해상도, 채널, 색공간 등 다양한 특성을 가지고 있으며, 이를 올바르게 처리하는 것이 모델 성능에 큰 영향을 미칩니다. 또한, 이미지 분류는 데이터의 다양한 특성을 기반으로 여러 방식으로 수행될 수 있습니다. 이번 포스팅에서는 이미지 데이터의 기본 성분, 전처리 기법, 그리고 다양한 분류 기법에 대해 알아보겠습니다.
1. 이미지 데이터의 기본 성분
해상도 (Resolution)
- 정의:
이미지의 가로×세로 픽셀 수 (예: 1920×1080).
해상도가 높을수록 이미지의 세부 정보가 많지만, 그만큼 메모리 사용량도 증가합니다.
픽셀 (Pixel)
- 정의:
이미지의 가장 작은 단위이며, 각 픽셀은 색상 정보를 담고 있습니다.
채널 (Channel)
- 정의:
각 픽셀이 가지는 색상 성분의 수로, 일반적으로 RGB 이미지의 경우 3채널 (Red, Green, Blue)을 사용합니다.
경우에 따라 그레이스케일, RGBA 등 다른 채널 구성을 사용하기도 합니다.
이미지 데이터의 메모리 사용
- 이슈:
일반적으로 이미지는 uint8 (1 byte) 형식으로 저장되지만, 전처리 과정에서 tensor화하고 normalize할 때 float32 (4 byte)로 변환되므로 메모리 사용량이 4배로 증가합니다.
2. 이미지 전처리와 EDA (Exploratory Data Analysis)
EDA (탐색적 데이터 분석)
이미지를 분석할 때 다음 사항들을 고려해야 합니다.
- 기본 정보:
차원, 채널, 이미지 크기, 파일 포맷 등 - 클래스 분포:
지도 학습의 경우, 라벨 분포 및 불균형 여부 - 샘플 확인:
이미지 하나하나를 확인하여 인사이트 도출 - 중복 이미지 제거:
해시 함수를 활용하여 중복된 이미지를 쉽게 제거
전처리를 통해 이미지의 의미 있는 feature와 representation을 추출하면, 모델의 성능과 일반화 능력을 크게 향상시킬 수 있습니다.
3. Color Space 변환
색공간(color space)은 색을 디지털적으로 표현하는 수학적 모델입니다.
일반적인 예로는 RGB, HSV, Lab, YCbCr, Grayscale 등이 있습니다.
OpenCV를 이용한 변환 예시는 다음과 같습니다:
import cv2
# 원본 BGR 이미지 로드
img = cv2.imread('image.jpg')
# BGR -> HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# BGR -> LAB
img_lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
# BGR -> YCrCb
img_ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCrCb)
# BGR -> Grayscale
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
또한, 히스토그램 평활화(histogram equalization) 를 통해 이미지의 contrast를 개선하고 디테일을 부각시킬 수 있습니다.
4. Geometric Transform & Data Augmentation
Geometric Transform
이미지의 형태나 크기, 위치 등을 변환하는 기법입니다.
- Translation (이동):
이미지 내 객체의 위치를 이동시킵니다. - Rotation (회전):
이미지를 일정 각도로 회전시킵니다. - Scaling (크기 조정):
이미지를 확대 또는 축소합니다. - Perspective Transformation (원근 변환):
특정 영역을 확대한 이미지로 변환하는 등, 시점 변화를 반영합니다.
예시 (회전):
import cv2
import numpy as np
row, col = img.shape[:2]
# 중심을 기준으로 90도 회전
matrix = cv2.getRotationMatrix2D((col/2, row/2), 90, 1)
new_img = cv2.warpAffine(img, matrix, (col, row))
Data Augmentation
데이터의 다양성을 높여 모델의 견고성과 일반화 성능을 향상시키기 위한 기법입니다.
- 일반 기법:
Flip, rotation, crop, color jittering 등 - Advanced 기법:
AutoAugment, RandAugment 등 데이터셋에 맞춰 최적의 정책을 자동 탐색하는 방법 - 라이브러리 활용:
Albumentations와 같은 라이브러리를 사용하여 손쉽게 다양한 augmentation을 적용할 수 있습니다.
예시 (Albumentations):
import albumentations as A
transform = A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.RandomCrop(height=224, width=224)
])
5. Normalization & Batch Normalization
Normalization
이미지의 픽셀 값을 일정 범위로 스케일링하는 기법으로, 모델 학습의 수렴 속도와 안정성을 개선합니다.
- Min-Max Normalization:
픽셀 값을 [0, 1] 범위로 스케일링 - Z-score Normalization (Standardization):
평균을 빼고 표준편차로 나눕니다.
예시 (PyTorch):
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
Batch Normalization
미니 배치 단위로 입력 데이터를 정규화하여 internal covariate shift를 줄이고, 높은 학습률과 안정성을 제공합니다.
6. 이미지 분류
이미지 분류는 주어진 이미지를 사전에 정의된 클래스에 할당하는 작업입니다.
분류 문제는 여러 방식으로 나뉩니다.
6-1. Binary Classification
- 설명:
데이터를 두 개의 클래스 중 하나로 분류합니다. - 예:
Yes/No, True/False 등 - 출력:
Sigmoid function을 통해 이진 결과 반환
6-2. Multi-Class Classification
- 설명:
데이터를 여러 클래스 중 하나로 분류합니다. - 출력:
Softmax function을 통해 각 클래스별 확률 분포 반환
6-3. Multi-Label Classification
- 설명:
하나의 이미지가 동시에 여러 클래스에 속할 수 있는 문제입니다. - 출력:
각 클래스마다 sigmoid function을 적용하여 독립적인 이진 분류 수행
6-4. Coarse-Grained vs. Fine-Grained Classification
- Coarse-Grained Classification:
상이한 범주 간의 분류 (예: 인라인 스케이트 vs 악어 vs 관람차 vs 사과) - Fine-Grained Classification:
동일 상위 범주 내에서 세부적인 하위 범주 분류 (예: 제비, 참새, 까마귀 등)
6-5. N-Shot Classification
- Few-Shot Classification:
각 클래스당 몇 개의 데이터만으로 학습하는 경우 - One-Shot Classification:
각 클래스당 단 하나의 예시만 학습 - Zero-Shot Classification:
학습 없이, 사전 지식을 바탕으로 예측
결론
이미지 데이터는 해상도, 픽셀, 채널, 색공간 등 다양한 성분으로 구성되며, 전처리 과정에서 메모리 사용과 계산 효율성에 큰 영향을 미칩니다.
- 전처리:
색공간 변환, geometric transform, augmentation, normalization 등 다양한 기법을 통해 이미지에서 의미 있는 정보를 추출하고, 모델 학습에 적합한 형태로 가공해야 합니다. - 분류 기법:
이미지 분류는 이진, 다중, 멀티라벨, 세밀한 분류 등 다양한 방식으로 이루어지며, 학습 데이터의 양과 품질에 따라 성능이 좌우됩니다. - EDA:
이미지 데이터의 기본 정보와 분포, 클래스 불균형 등을 분석하여, 중복 제거 및 추가 전처리를 수행하는 것이 중요합니다.
Inductive Bias와 Representation: 모델의 선입견이 만드는 데이터 표현
머신 러닝 모델은 데이터를 단순히 암기하지 않고, 일반화된 패턴을 학습하기 위해 특정 가정을 내포합니다. 이를 inductive bias(귀납적 편향) 라고 하며, 이 bias가 모델이 데이터를 어떻게 해석하고 표현하는지 결정하는 핵심 요소입니다.
1. Inductive Bias란?
Inductive bias는 모델이 학습할 때 데이터에서 특정 패턴이나 관계를 찾으려는 경향, 혹은 데이터를 특정 방식으로 해석하려는 가정을 의미합니다.
예를 들어:
- 선형 회귀 모델은 데이터 간에 직선 형태의 관계가 존재한다는 가정을 내포합니다.
- Decision Tree는 데이터를 계층적인 의사결정 트리 구조로 분류하려고 합니다.
만약 모델에 inductive bias가 없다면, 모델은 단순히 데이터를 암기(overfitting)하게 되어 새로운 데이터에 대해 일반화 능력이 크게 떨어지게 됩니다. 이러한 bias를 이해하면, 문제의 특성에 맞는 모델을 선택하고 설계할 수 있습니다.
2. Representation (표현)이란?
Representation은 모델 내부에서 데이터가 어떻게 변환되고 다뤄지는지를 의미합니다.
- 이미지:
원래 픽셀 값(0~255)은 모델이 바로 이해하기 어렵기 때문에, Convolutional Neural Network(CNN)는 이를 feature map으로 변환해 중요한 패턴과 구조를 학습합니다. - 텍스트:
인간은 텍스트를 바로 이해하지만, 모델은 단어 자체가 아닌 벡터로 변환해 단어들 사이의 관계를 학습합니다. - 시계열 데이터:
RNN이나 LSTM과 같은 모델은 시간의 흐름을 반영한 representation을 생성하여 주식 차트 등에서 패턴을 포착합니다.
딥러닝에서는 feature engineering 없이도 모델이 자동으로 representation을 학습하지만, 이 representation은 모델의 inductive bias에 크게 영향을 받습니다.
3. Representation은 Inductive Bias의 산물이다
결국, 모델이 데이터를 어떻게 표현하는지는 그 모델이 가지는 inductive bias에 의해 결정됩니다.
- 모델의 구조와 가정:
각 모델은 특정한 구조적 가정(예: CNN은 지역적 패턴, RNN은 순차적 관계)을 가지고 있습니다. 이러한 가정이 데이터로부터 어떤 feature를 추출할지, 그리고 이 feature들이 어떻게 표현될지를 결정합니다. - 자동 학습 vs. 수동 feature engineering:
전통적인 머신 러닝에서는 사람이 직접 feature engineering을 수행했지만, 딥러닝에서는 모델이 스스로 representation을 학습합니다. 그러나 이 또한 모델의 구조와 설계, 즉 inductive bias에 따라 좌우됩니다.
따라서, representation은 결국 모델의 inductive bias의 산물입니다. 이 말은, 모델이 데이터에서 어떤 패턴을 학습할지, 그리고 학습한 패턴을 어떤 방식으로 표현할지는 모델이 내포하고 있는 선입견에 따라 결정된다는 의미입니다.
CNN, ViT, 그리고 Hybrid 모델: Computer Vision의 새로운 패러다임
컴퓨터 비전 분야에서는 오랜 기간 동안 Convolutional Neural Network (CNN)이 표준 모델로 자리 잡아왔습니다. 최근에는 Transformer 기반의 Vision Transformer (ViT)가 주목받으며, CNN의 한계를 보완하는 Hybrid 모델들도 활발하게 연구되고 있습니다. 이번 포스팅에서는 각 모델의 기본 개념과 특징, 그리고 서로의 장점을 결합한 Hybrid 모델의 예시를 살펴보겠습니다.
1. Convolutional Neural Network (CNN)
- 주요 특징:
- Grid 형태의 데이터 처리: 이미지처럼 2차원 데이터를 처리하기 적합
- 구성 요소:
- Convolutional layer: 국소적인 패턴 추출
- Pooling layer: 공간적 크기를 줄이고 특징을 요약
- Fully Connected layer: 최종 분류를 위한 통합
- 계층적 표현 학습:
- 저수준부터 고수준까지 점진적으로 의미 있는 feature를 학습
CNN은 오랜 연구 기간 동안 이미지 처리에서 강력한 성능을 보여주었으며, 지역적 패턴을 효과적으로 학습하는 능력이 뛰어납니다.
2. ConvNeXt
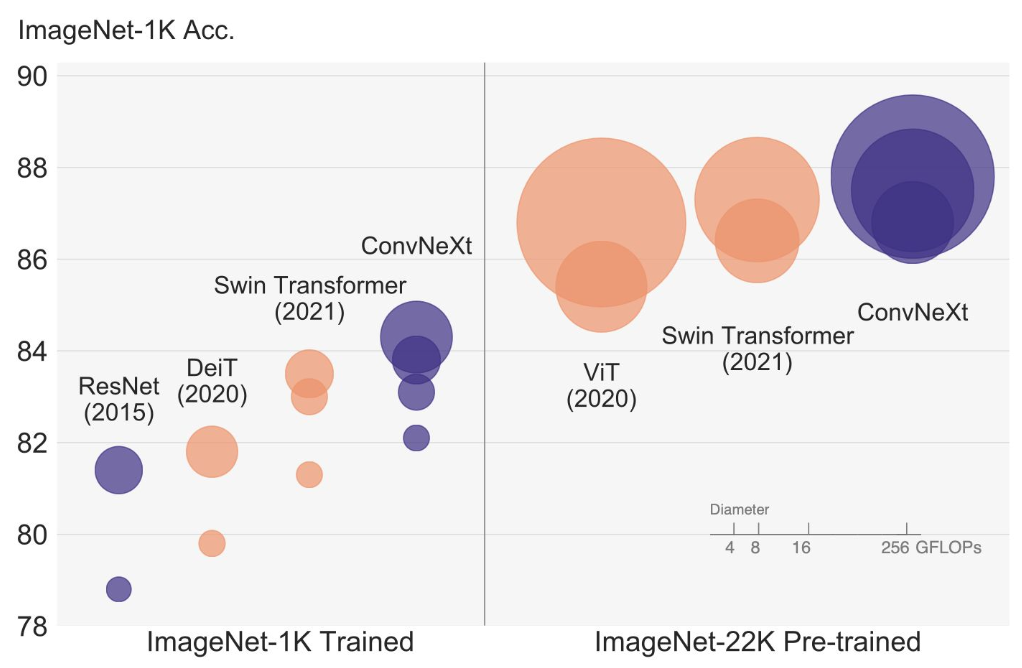
ConvNeXt는 기존 CNN의 강점을 유지하면서 최신 딥러닝 기법을 도입한 모델입니다.
- 핵심 기술:
- Depthwise Convolution: 효율적인 convolution 연산을 위해 depthwise와 pointwise convolution으로 분리
- Layer Normalization: 안정적인 학습 및 Transformer 스타일 학습 기법 도입
- 7×7 Kernel: 더 넓은 범위에서 특징을 추출하여 ViT의 patch와 유사한 역할
- GELU Activation, Inverted Bottleneck: 파라미터 효율성을 극대화하고 연산량을 줄여 성능 최적화
- 성능:
- 대규모 데이터셋에서는 ViT가 우수한 성능을 보이지만, 작은 데이터셋에서는 ConvNeXt가 더 유리할 수 있음
- 구조가 단순하고 연산 효율성이 높아 실시간 어플리케이션에도 적합
3. Vision Transformer (ViT)
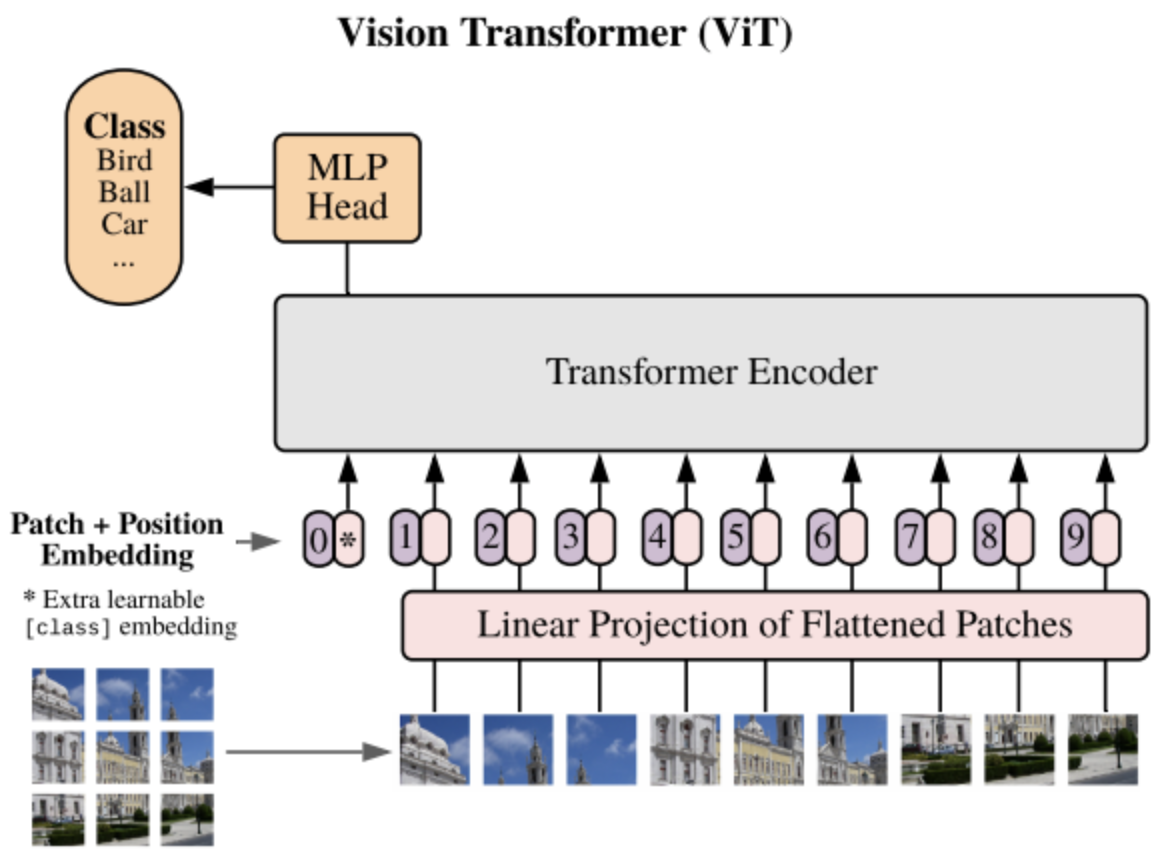
ViT는 Transformer 모델을 Computer Vision에 적용한 대표적인 모델입니다.
- 주요 구성 요소:
- Patch Embedding: 이미지를 작은 패치로 분할한 후, 선형 투영을 통해 embedding 벡터로 변환
- Position Embedding: 패치의 순서 정보를 학습 가능한 위치 임베딩으로 추가
- Encoder: Self-Attention과 Feed-Forward layer가 쌓여, 패치 간의 장거리 의존성을 학습
- Classification Head: Global Average Pooling 및 선형 layer를 통해 최종 클래스 확률 예측
- 특징:
- 전역적 관계를 효과적으로 모델링할 수 있어 장거리 의존성에 강함
- 입력 이미지의 크기가 가변적이라는 장점이 있으나, 계산 비용이 많이 들고 데이터 효율성이 낮은 단점이 있음
4. CNN vs. ViT 비교
| 항목 | CNN | ViT |
|---|---|---|
| Local Pattern 학습 | 강점 (convolution 기반) | 상대적으로 약함 |
| 계산 효율성 | 높은 효율성 | 연산 비용이 높음 |
| 가변 크기 입력 | 고정 크기 필요 | 가변 입력 지원 |
| 장거리 의존성 | 한계 존재 | 효과적 (Self-Attention) |
| 데이터 효율성 | 소규모 데이터에 유리 | 대규모 데이터 필요 |
5. Hybrid 모델: CNN과 ViT의 장점을 결합
Hybrid 모델은 CNN과 ViT의 장점을 모두 활용하여, 서로의 단점을 보완하는 방향으로 개발됩니다. 대표적인 예가 CoAtNet입니다.
CoAtNet

- 설계:
- s-stage 구조: C-C-T-T (Convolutional - Convolutional - Transformer - Transformer)로 구성하여, 초기 단계에서는 CNN을, 후반 단계에서는 Transformer를 사용
- 점진적 해상도 감소와 채널 증가: 이미지의 다양한 scale 정보를 효과적으로 처리
- 장점:
- 소량의 데이터로도 좋은 generalization
- 빠른 수렴 및 효율적인 학습
- 대규모 데이터셋에서 우수한 scalability
- ViT보다 적은 사전 학습 데이터와 계산량 필요
그 외에도 ConViT, CvT, LocalViT 등 다양한 hybrid 모델들이 개발되고 있습니다.
결론
- CNN: 지역적 패턴 학습과 높은 계산 효율성에서 강점을 보이며, 전통적인 컴퓨터 비전 문제에서 오랜 기간 표준 모델로 자리잡았습니다.
- ViT: Transformer 기반의 전역적 관계 학습을 통해 장거리 의존성 문제를 해결하지만, 계산 비용과 데이터 요구량이 높습니다.
- Hybrid 모델 (예: CoAtNet): CNN과 ViT의 장점을 결합하여, 적은 데이터와 계산량으로도 높은 성능을 발휘하며, 두 모델의 단점을 효과적으로 보완합니다.
Transfer Learning, Self-Supervised Learning, Multimodal Learning, 그리고 Foundation Models
최근 AI 분야에서는 모델의 성능 향상을 위해 단순히 모델 구조를 개선하는 것뿐만 아니라, 데이터를 어떻게 활용하고, 다양한 정보를 결합하느냐가 중요한 화두로 떠올랐습니다. 특히, Transfer Learning, Self-Supervised Learning, Multimodal Learning, 그리고 Foundation Model은 AI 개발의 새로운 패러다임으로 주목받고 있습니다. 이 포스트에서는 각각의 개념과 장점을 살펴보고, 실제 애플리케이션에서 어떻게 활용되는지 알아보겠습니다.
1. Transfer Learning (전이 학습)
Transfer Learning은 한 도메인 또는 태스크에서 사전 학습된 모델을 다른 도메인에 적용하는 학습 방법입니다.
예를 들어, ImageNet에서 훈련된 모델을 의료 영상이나 위성 사진과 같이 전혀 다른 도메인에 적용할 수 있습니다.
주요 특징
- 적은 데이터로도 빠른 학습 및 성능 향상:
이미 학습된 일반적인 feature들을 활용하기 때문에, target task에서 필요한 데이터 양이 적어도 빠른 수렴과 좋은 성능을 얻을 수 있습니다. - 학습 방식:
- 가중치 고정 후 학습: Source task에서 학습한 모델의 가중치를 고정하고, classifier 등 일부 계층만 학습
- 전체 모델 fine-tuning: 모든 가중치를 업데이트하여 target task에 맞게 조정
- 일부 Layer만 고정: 하위 레이어(일반 feature 추출)는 고정하고, 상위 레이어(태스크 특화)는 학습
주의사항
- Fine-Grained Task:
매우 세밀한 태스크의 경우, Transfer Learning보다 충분한 target 데이터 확보가 더욱 큰 성능 향상을 가져올 수 있습니다.
2. Self-Supervised Learning
Self-Supervised Learning은 모델이 데이터 자체로부터 라벨을 생성하고, 그 라벨을 바탕으로 학습하는 방법입니다.
수동으로 라벨링하는 과정이 시간과 비용을 많이 들게 하는 문제를 해결할 수 있으며, 더 일반화된 representation을 학습할 수 있습니다.
Pretext 작업 예시
- Colorization:
흑백 이미지를 컬러 이미지로 복원하는 작업 - Inpainting:
이미지의 빈 영역을 채워 넣는 작업 - Jigsaw Puzzle Solving:
이미지를 여러 조각으로 나눈 후, 올바른 순서로 재구성하는 작업 - Rotation Prediction:
회전시킨 이미지의 회전 각도를 예측하는 작업 - Contrastive Learning:
같은 이미지의 다양한 augmentation 버전은 positive pair로, 다른 이미지들은 negative pair로 간주하여 학습
이러한 pretext 작업을 통해 학습된 representation은 이후 Transfer Learning의 사전 학습 단계로 활용되어, 다양한 downstream 태스크에서 성능을 높일 수 있습니다.
3. Multimodal Learning
Multimodal Learning은 하나의 데이터를 다양한 modality (예: vision, audio, text 등)로 표현하여 얻은 정보를 결합해 학습하는 방법입니다.
주요 활용 예시
- Vision-Language Models:
예를 들어, CLIP, ALIGN, FLAVA 등은 이미지와 텍스트를 동시에 이해하여 zero-shot classification, image-text retrieval, visual question answering, image captioning 등의 태스크에서 뛰어난 성능을 보여줍니다.
장점
- 각 modality가 가진 상호 보완적 특성을 활용하여, 단일 modality보다 더 풍부하고 일반화된 representation을 학습할 수 있습니다.
- 다양한 데이터 소스로부터 얻은 정보를 결합함으로써, 복잡한 실제 상황에 더 잘 대응할 수 있습니다.
4. Foundation Models
Foundation Model은 대규모 데이터에 대해 사전 학습된 모델로, 다양한 downstream 태스크에 채택될 수 있는 범용 모델입니다.
특징
- 대규모 Pre-training:
방대한 데이터셋을 사용해 일반적인 representation을 학습합니다. - Transferability:
학습된 모델은 다양한 작업(예: 텍스트 생성, 이미지 분류, multimodal tasks 등)에 쉽게 적응할 수 있습니다.
대표 예시
- Language Models:
GPT, BERT 등 - Vision Models:
CLIP, DALL·E 등 - Multimodal Models:
SAM, Whisper, Flamingo 등
Foundation Models는 AI의 여러 분야에서 강력한 성능의 기반이 되며, 적은 추가 데이터로도 다양한 작업에 쉽게 fine-tuning 할 수 있는 장점이 있습니다.
결론
현대 AI는 사전 학습된 모델의 재활용과 데이터로부터 자동으로 얻은 표현(representation)을 바탕으로 빠르고 효율적인 학습을 가능하게 합니다.
- Transfer Learning을 통해 적은 데이터로도 빠른 학습과 높은 성능을 달성할 수 있으며,
- Self-Supervised Learning은 라벨 없이도 강력한 representation을 학습할 수 있는 경제적인 방법입니다.
- Multimodal Learning은 다양한 데이터를 결합해 보다 풍부한 정보를 활용하고,
- Foundation Models는 여러 분야에 걸쳐 범용적으로 활용 가능한 강력한 기반 모델로 자리잡고 있습니다.
이러한 패러다임들을 이해하고 적절히 활용하면, 더욱 효율적이고 범용적인 AI 시스템을 구축할 수 있습니다.
Computer Vision: 이미지 분류 모델 학습 프로세스
이미지 분류는 주어진 이미지를 사전에 정의된 클래스에 할당하는 작업입니다. 이 포스팅에서는 데이터셋 구축부터 모델 정의, 학습, 그리고 평가까지 이미지 분류 모델을 학습시키는 전반적인 프로세스를 살펴봅니다.
1. 데이터셋 구축과 DataLoader
Dataset 클래스
데이터셋 클래스는 이미지 데이터와 그에 해당하는 라벨을 로드하고, 전처리 및 배치 처리를 쉽게 할 수 있도록 도와줍니다. Dataset 클래스는 두 가지 필수 메서드를 포함해야 합니다.
__len__: 전체 아이템 수 반환__getitem__: 주어진 인덱스에 해당하는 데이터를 전처리하여 반환
import os
import pandas as pd
from torch.utils.data import Dataset
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
DataLoader
DataLoader는 Dataset으로부터 데이터를 배치(batch) 단위로 로드해 줍니다. 이를 통해 모델 학습 시 메모리 사용 최적화와 학습 속도를 높일 수 있습니다.
from torch.utils.data import DataLoader
train_dataset = CustomImageDataset("train_annotations.csv", "./train_images")
test_dataset = CustomImageDataset("test_annotations.csv", "./test_images")
train_dataloader = DataLoader(
train_dataset,
batch_size=64,
shuffle=True,
num_workers=0,
drop_last=True)
test_dataloader = DataLoader(
test_dataset,
batch_size=64,
shuffle=False,
num_workers=0,
drop_last=False)
2. 모델 정의
모델은 직접 구성할 수도 있고, torchvision이나 timm과 같은 라이브러리를 활용할 수도 있습니다. 아래는 간단한 CNN 모델의 예시입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 입력 채널 3, 출력 채널 6, kernel size 5
self.pool = nn.MaxPool2d(2, 2) # 2x2 max pooling
self.conv2 = nn.Conv2d(6, 16, 5) # 두 번째 convolution layer
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # 10개 클래스 분류
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = torch.flatten(x, 1) # 배치 차원 제외 모든 차원 flatten
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
3. 손실 함수 (Loss Function)
모델의 예측 값과 실제 라벨 사이의 차이를 측정하는 손실 함수는 학습의 핵심 요소입니다. 다중 클래스 분류 문제에는 보통 CrossEntropyLoss를 사용합니다.
import torch.nn as nn
loss_fn = nn.CrossEntropyLoss(
weight=None, # 클래스 불균형 조절 시 사용
ignore_index=-100, # 특정 label은 무시
reduction='mean', # 평균 손실 값 반환
label_smoothing=0.0 # 라벨 스무딩 적용 (과적합 방지)
)
# 예시: loss = loss_fn(predictions, labels)
기타 손실 함수로는 NLLLoss, BCELoss, BCEWithLogitsLoss, F1 Loss, Focal Loss 등이 있으며, 문제에 맞게 선택합니다.
4. Optimizer
Optimizer는 손실 함수가 최소화되는 방향으로 모델 파라미터를 업데이트합니다. 일반적으로 SGD와 Adam이 많이 사용됩니다.
import torch.optim as optim
optimizer = optim.Adam(
net.parameters(),
lr=0.001,
betas=(0.9, 0.999),
weight_decay=0.01)
5. Learning Rate Scheduler
학습률(Learning Rate)은 모델의 파라미터 업데이트 크기를 결정합니다. 학습 초기에 높은 학습률을 사용하여 빠르게 학습하고, 이후에는 점진적으로 학습률을 낮춰 수렴 과정을 안정화합니다. 대표적인 스케줄러로는 StepLR, ExponentialLR, CosineAnnealingLR, ReduceLROnPlateau 등이 있습니다.
6. Training & Validation Process
Training Loop
모델 학습은 아래와 같은 단계로 진행됩니다:
- 데이터와 모델을 GPU 또는 CPU로 이동
- 모델을 training 모드로 전환
- 배치별로 예측 수행, 손실 계산, backpropagation, optimizer 업데이트, learning rate scheduler 업데이트
- 배치별 손실을 누적하여 epoch당 평균 손실 계산
from tqdm import tqdm
def train_epoch(model, train_loader, optimizer, loss_fn, scheduler, device):
model.train()
total_loss = 0.0
progress_bar = tqdm(train_loader, desc="Training", leave=False)
for images, targets in progress_bar:
images, targets = images.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
scheduler.step()
total_loss += loss.item()
progress_bar.set_postfix(loss=loss.item())
return total_loss / len(train_loader)
Validation Loop
평가 시에는 모델을 평가 모드로 전환한 후, gradient 계산 없이 진행합니다.
def validate(model, val_loader, loss_fn, device):
model.eval()
total_loss = 0.0
progress_bar = tqdm(val_loader, desc='Validating', leave=False)
with torch.no_grad():
for images, targets in progress_bar:
images, targets = images.to(device), targets.to(device)
outputs = model(images)
loss = loss_fn(outputs, targets)
total_loss += loss.item()
progress_bar.set_postfix(loss=loss.item())
return total_loss / len(val_loader)
전체 Training Process
def train(model, train_loader, val_loader, optimizer, loss_fn, scheduler, epochs, device):
for epoch in range(epochs):
train_loss = train_epoch(model, train_loader, optimizer, loss_fn, scheduler, device)
val_loss = validate(model, val_loader, loss_fn, device)
print(f"Epoch {epoch+1}: Train Loss = {train_loss:.4f}, Val Loss = {val_loss:.4f}")
# 모델 저장, scheduler 업데이트 등 추가 작업 수행
- Step vs. Epoch:
- Step: 하나의 minibatch가 모델을 통과하여 파라미터가 업데이트되는 과정
- Epoch: 전체 학습 데이터셋이 한 번 모델을 통과한 주기
결론
이미지 분류 모델 학습 프로세스는 데이터셋 구축과 전처리, DataLoader를 통한 배치 처리, 모델 정의, 손실 함수와 optimizer, 그리고 learning rate scheduler 설정 및 training/validation loop로 구성됩니다.
이러한 전체 파이프라인을 체계적으로 구성하면, 효과적으로 모델을 학습시키고 평가할 수 있으며, 나아가 성능 개선에 큰 도움이 됩니다.
모델 학습 속도 향상을 위한 효율적인 기법들
모델 학습 속도가 지나치게 느릴 때는 여러 효율적인 방법들을 적용하여 학습 시간을 단축할 수 있습니다. 이 포스팅에서는 데이터 캐싱, 그라디언트 누적, 혼합 정밀도 학습, pseudo labeling, 그리고 생성 모델을 활용한 데이터 증강 기법에 대해 알아보겠습니다.
1. Data Caching
데이터 I/O가 학습 속도의 병목이 될 수 있습니다. 특히 이미지와 같이 용량이 큰 데이터를 매 epoch마다 디스크에서 불러오면 큰 오버헤드가 발생합니다.
해결법:
- 전체 이미지를 미리 메모리로 불러와 vector화한 후 npy 파일로 저장하고, 이후에는 이 npy 파일을 불러와 사용합니다.
def data_caching(root_dir: str, info_df: pd.DataFrame):
for idx, row in info_df.iterrows():
image_path = os.path.join(root_dir, row['image_path'])
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
npy_path = image_path.replace('.jpg', '.npy')
np.save(npy_path, image)
data_caching('base_directory', info_df)
- Dataset 클래스에서는 이미지가 메모리에 로드되어 있지 않으면 새롭게 불러오고, 이미 로드된 데이터는 재사용하도록 구현합니다.
class CustomImageDataset(Dataset):
def __init__(self, info_df, root_dir, transform=None):
self.info_df = info_df
self.root_dir = root_dir
self.transform = transform
self.images = [None] * len(info_df) # 캐시용 리스트
def __len__(self):
return len(self.info_df)
def __getitem__(self, index):
if self.images[index] is None:
img_path = os.path.join(self.root_dir, self.info_df.iloc[index]['image_path'])
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
self.images[index] = image
else:
image = self.images[index]
label = self.info_df.iloc[index]['label']
if self.transform:
image = self.transform(image)
return image, label
주의: 전체 데이터셋이 메모리 용량을 초과하지 않도록 주의해야 합니다.
2. Gradient Accumulation
메모리 제약으로 인해 작은 batch size를 사용할 경우, gradient 추정이 불안정해질 수 있습니다.
해결법:
- 여러 미니 배치의 gradient를 누적한 후, 일정 step마다 optimizer로 업데이트합니다.
- 이렇게 하면 작은 batch size로도 큰 batch 효과를 낼 수 있습니다.
accumulation_steps = 10
optimizer.zero_grad() # loop 바깥에서 초기화
for i, (images, targets) in enumerate(progress_bar):
images, targets = images.to(device), targets.to(device)
outputs = model(images)
loss = loss_fn(outputs, targets)
loss = loss / accumulation_steps # 평균화
loss.backward()
total_loss += loss.item()
if (i + 1) % accumulation_steps == 0 or (i + 1) == len(train_loader):
optimizer.step()
optimizer.zero_grad()
scheduler.step() # 업데이트 시에만 step
3. Mixed Precision Training
학습 시 float32를 사용하면 정밀도는 높지만 메모리 사용량과 연산 비용이 커집니다.
해결법:
- Mixed Precision Training은 float16 또는 bfloat16과 float32를 적절히 혼합하여 사용함으로써 연산 속도와 메모리 효율성을 향상시킵니다.
- PyTorch의
torch.cuda.amp모듈을 사용합니다.
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for images, targets in train_loader:
optimizer.zero_grad()
images, targets = images.to(device), targets.to(device)
with autocast():
outputs = model(images)
loss = loss_fn(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
4. Pseudo Labeling
대규모 unlabeled 데이터셋의 경우, 직접 라벨링하는 비용과 시간이 많이 듭니다.
Pseudo Labeling 방법:
- 모델 학습: labeled 데이터를 사용해 초기 모델 학습
- 예측: 학습된 모델을 이용해 unlabeled 데이터에 대한 예측 수행
- 신뢰도 기준 선택: 높은 신뢰도의 예측 결과를 pseudo label로 선택
- 재학습: labeled 데이터와 pseudo labeled 데이터를 함께 사용해 모델을 재학습
주의: validation set은 pseudo labeling에 포함시키지 않아야 합니다.
5. Generative Models를 활용한 데이터 증강
생성 모델(text-to-image, image-to-image)을 활용하면 추가 데이터를 생성할 수 있습니다.
- 활용 사례:
- CLIP 등을 활용해 생성된 이미지가 의도한 표현을 포함하는지 평가
- 부족한 데이터 영역을 보완하여 학습 데이터의 다양성과 양을 증가시킴
단, 생성된 데이터가 실제와 유사한지 검증하는 과정이 필요합니다.
결론
모델 학습 속도가 느릴 때는 다양한 효율적인 기법들을 적용해 전체 파이프라인의 속도를 개선할 수 있습니다.
- Data Caching을 통해 반복적인 디스크 I/O를 줄이고,
- Gradient Accumulation을 활용해 작은 배치에서도 안정적인 학습을,
- Mixed Precision Training으로 연산 효율성을 높이며,
- Pseudo Labeling과 Generative Models를 통해 추가 데이터를 확보함으로써, 전반적인 학습 효율을 극대화할 수 있습니다.
이러한 기법들을 적절히 조합하면, 학습 속도는 물론 최종 모델 성능까지 개선할 수 있으므로, 실무에서 매우 유용하게 활용될 수 있습니다.
---아래는 모델 학습 속도 향상을 위한 효율적인 기법들을 정리한 최종 블로그 포스트 초안입니다.
모델 학습 속도 향상을 위한 효율적인 기법들
모델 학습 속도가 지나치게 느릴 때는 여러 효율적인 방법들을 적용하여 학습 시간을 단축할 수 있습니다. 이번 포스팅에서는 데이터 캐싱, 그라디언트 누적(Gradient Accumulation), 혼합 정밀도 학습(Mixed Precision Training), Pseudo Labeling, 그리고 생성 모델을 활용한 데이터 증강 기법에 대해 알아보겠습니다.
1. Data Caching
데이터 I/O가 학습 속도의 병목이 될 수 있습니다. 특히 이미지와 같이 용량이 큰 데이터를 매 epoch마다 디스크에서 불러오면 큰 오버헤드가 발생합니다.
해결법:
- 전체 이미지를 미리 메모리로 불러와 vector화한 후, npy 파일로 저장하고 이후에는 이 npy 파일을 불러와 사용합니다.
def data_caching(root_dir: str, info_df: pd.DataFrame):
for idx, row in info_df.iterrows():
image_path = os.path.join(root_dir, row['image_path'])
image = cv2.imread(image_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
npy_path = image_path.replace('.jpg', '.npy')
np.save(npy_path, image)
data_caching('base_directory', info_df)
- Dataset 클래스에서는 이미지가 메모리에 로드되어 있지 않으면 새롭게 불러오고, 이미 로드된 데이터는 재사용하도록 구현합니다.
class CustomImageDataset(Dataset):
def __init__(self, info_df, root_dir, transform=None):
self.info_df = info_df
self.root_dir = root_dir
self.transform = transform
self.images = [None] * len(info_df) # 캐시용 리스트
def __len__(self):
return len(self.info_df)
def __getitem__(self, index):
if self.images[index] is None:
img_path = os.path.join(self.root_dir, self.info_df.iloc[index]['image_path'])
image = cv2.imread(img_path, cv2.IMREAD_COLOR)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
self.images[index] = image
else:
image = self.images[index]
label = self.info_df.iloc[index]['label']
if self.transform:
image = self.transform(image)
return image, label
주의: 전체 데이터셋이 메모리 용량을 초과하지 않도록 주의해야 합니다.
2. Gradient Accumulation
메모리 제약으로 인해 작은 batch size를 사용할 경우, gradient 추정이 불안정해질 수 있습니다.
해결법:
- 여러 미니 배치의 gradient를 누적한 후, 일정 step마다 optimizer로 업데이트합니다. 이렇게 하면 작은 batch size로도 큰 batch 효과를 낼 수 있습니다.
accumulation_steps = 10
optimizer.zero_grad() # loop 바깥에서 초기화
for i, (images, targets) in enumerate(progress_bar):
images, targets = images.to(device), targets.to(device)
outputs = model(images)
loss = loss_fn(outputs, targets)
loss = loss / accumulation_steps # 평균화
loss.backward()
total_loss += loss.item()
if (i + 1) % accumulation_steps == 0 or (i + 1) == len(train_loader):
optimizer.step()
optimizer.zero_grad()
scheduler.step() # 업데이트 시에만 step
3. Mixed Precision Training
학습 시 float32를 사용하면 정밀도는 높지만 메모리 사용량과 연산 비용이 커집니다.
해결법:
- Mixed Precision Training은 float16 또는 bfloat16과 float32를 적절히 혼합하여 사용함으로써 연산 속도와 메모리 효율성을 향상시킵니다.
- PyTorch의
torch.cuda.amp모듈을 사용합니다.
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
for images, targets in train_loader:
optimizer.zero_grad()
images, targets = images.to(device), targets.to(device)
with autocast():
outputs = model(images)
loss = loss_fn(outputs, targets)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
4. Pseudo Labeling
대규모 unlabeled 데이터셋의 경우, 직접 라벨링하는 비용과 시간이 많이 듭니다.
Pseudo Labeling 방법:
- 모델 학습: labeled 데이터를 사용해 초기 모델을 학습합니다.
- 예측: 학습된 모델을 이용해 unlabeled 데이터에 대한 예측을 수행합니다.
- 신뢰도 기준 선택: 높은 신뢰도의 예측 결과를 pseudo label로 선택합니다.
- 재학습: labeled 데이터와 pseudo labeled 데이터를 함께 사용해 모델을 재학습합니다.
주의: Validation set은 pseudo labeling 과정에 포함시키지 않아야 합니다.
5. Generative Models를 활용한 데이터 증강
생성 모델(text-to-image, image-to-image)을 활용하면 학습에 사용할 추가 데이터를 생성할 수 있습니다.
- 활용 사례:
- 예를 들어, CLIP 등의 모델로 생성된 이미지가 의도한 표현(text)을 포함하는지 평가하여, 부족한 데이터 영역을 보완할 수 있습니다.
- 이를 통해 학습 데이터의 다양성과 양을 증가시켜, 모델 성능을 향상시킬 수 있습니다.
단, 생성된 데이터의 신뢰성을 검증하는 과정이 필요합니다.
결론
모델 학습 속도가 느릴 때는 다음과 같은 효율적인 기법들을 적절히 조합하여 전체 학습 파이프라인의 속도를 개선할 수 있습니다.
- Data Caching: 반복적인 디스크 I/O를 줄여 데이터 로딩 시간을 단축합니다.
- Gradient Accumulation: 작은 배치로도 큰 배치 효과를 내어 학습의 안정성과 성능을 향상시킵니다.
- Mixed Precision Training: 메모리 사용량과 연산 비용을 줄이면서 학습 속도를 높입니다.
- Pseudo Labeling: 추가 unlabeled 데이터를 효과적으로 활용하여 학습 데이터를 증강합니다.
- Generative Models: 생성 모델을 활용해 데이터 다양성을 높이고, 부족한 데이터 영역을 보완합니다.
이러한 기법들을 통해 학습 속도와 최종 모델 성능을 동시에 개선할 수 있으며, 실무에서 효율적인 학습 파이프라인 구축에 큰 도움이 될 것입니다.
Confusion Matrix와 Ensemble 기법을 활용한 분류 성능 평가
머신러닝 모델의 성능을 평가할 때, confusion matrix는 예측 결과와 실제 라벨을 한눈에 비교할 수 있는 강력한 도구입니다. 이를 통해 accuracy, precision, recall, 그리고 F1-score와 같은 여러 성능 지표를 산출할 수 있습니다. 또한, 여러 모델의 예측을 결합하는 ensemble 기법을 활용하면 성능을 더욱 높일 수 있습니다. 이 포스팅에서는 confusion matrix의 구성과 각 지표의 의미, 그리고 ensemble 기법들에 대해 살펴보겠습니다.
1. Confusion Matrix란?

Confusion Matrix는 모델의 예측 결과와 실제 라벨을 비교하여 다음 네 가지 항목으로 분류한 행렬입니다.
- True Positive (TP): 올바르게 긍정으로 예측한 경우
- True Negative (TN): 올바르게 부정으로 예측한 경우
- False Positive (FP): 부정임에도 긍정으로 잘못 예측한 경우
- False Negative (FN): 긍정임에도 부정으로 잘못 예측한 경우
이러한 구성 요소를 기반으로 다양한 성능 지표를 계산할 수 있습니다.
주요 성능 지표
-
Accuracy (정확도): 전체 예측 중 올바른 예측의 비율
-
Precision (정밀도): 긍정으로 예측한 항목 중 실제 긍정의 비율
-
Recall (재현율): 실제 긍정 항목 중 모델이 긍정으로 예측한 비율
-
F1-Score: Precision과 Recall의 조화 평균
성능 지표 선택의 중요성
문제의 정의에 따라 어떤 성능 지표를 우선시해야 하는지가 달라집니다. 예를 들어:
- 쓰레기 처리장 시스템:
재산 피해가 크지 않으므로, 잘못된 경보(False Positive)가 문제가 됩니다. 이 경우 precision을 중시해야 합니다. - 금은방 시스템:
한 번의 절도도 큰 피해로 이어지므로, 실제 도둑을 잡는 능력(Recall)이 더 중요합니다.
어떤 지표를 사용할지 결정할 때, 상황에 맞는 threshold를 선택하여 비용을 최소화하는 것이 중요합니다.
2. Ensemble 기법
Ensemble 기법은 동일한 태스크에 대해 여러 모델의 예측을 결합하여, 개별 모델의 약점을 보완하고 성능을 향상시키는 방법입니다.
주요 Ensemble 기법
-
Voting:
여러 모델이 예측한 결과를 투표하여 최종 예측을 결정합니다.
Weighted Ensemble의 경우, 성능이 좋은 모델에 더 많은 가중치를 부여하여 전체 결과에 미치는 영향을 증대시킵니다. -
Cross-Validation:
여러 모델을 서로 다른 데이터 분할로 학습하고, 이들의 예측을 결합하여 모델의 일반화 성능을 높입니다. -
Test-Time Augmentation (TTA):
테스트 데이터에 다양한 augmentation(예: flip, rotation 등)을 적용하여 여러 번 예측한 후, 그 결과를 평균 내거나 결합합니다. 이를 통해 모델의 예측이 보다 견고해집니다.
결론
- Confusion Matrix는 모델의 TP, TN, FP, FN을 통해 accuracy, precision, recall, F1-score 등 다양한 성능 지표를 산출할 수 있으며, 문제의 정의에 따라 적절한 평가 지표와 threshold를 선택하는 것이 중요합니다.
- Ensemble 기법은 여러 모델의 예측을 결합하여 단일 모델보다 더 뛰어난 성능과 안정성을 제공합니다. Weighted Voting, Cross-Validation, 그리고 Test-Time Augmentation 등 다양한 방법을 활용할 수 있습니다.