Attention 논문 리뷰
1. Abstract
- 기존의 Sequence 변환 모델은 대부분 인코더와 디코더를 포함하는 RNN 또는 CNN 신경망에 기반을 두고 있음
- 해당 논문에서는 Attention 매커니즘만을 이용한 모델 구조인 Transformer를 제안함
⇒ Attention이란 문맥에 따라 집중할 단어를 결정하는 방식을 의미 - Transformer의 특징은 아래와 같음
- 더 높은 병렬화가 가능해 기존 모델들 보다 학습 시간이 덜 걸림
- WMT 2014 영어-독일어 및 영어-프랑스어 번역 작업에서 Transformer는 최신 성능을 기록
2. Introduction
- 순차적 데이터를 처리하기 위해 주로 RNN이나 CNN이 사용되어 왔음
⇒ 이러한 모델들은 성능은 뛰어나지만 긴 종속관계를 학습하는 데 어려움이 있음 또는 Suquence 길이가 길어지면 메모리 문제가 발생할 수 있음 - 이러한 문제를 해결하기 위해 RNN, CNN 없이 Attention 매커니즘만을 사용한 새로운 모델 구조인 Transformer를 제안
3. Background
- Extended Neural GPU, ByteNet, ConvS2S 에서도 연속적 연산을 줄이기 위한 연구가 이루어졌는데, 모두 CNN을 기본 구성 요소로 사용
⇒ 병렬 처리가 가능하지만, 입력값과 출력값이 멀수록 의존성을 알기 어렵고 계산량 증가 - 하지만 Transformer를 사용하면 Multi-Head Attention을 이용해 상수 시간의 값으로 계산이 가능
3.1 Self Attention
- 말 그대로 Attention을 자기 자신한테 취한다는 것 ⇒ 문장에서의 단어들 간의 연관성을 알기위해
위 그림과 같이 문장 내에서 it 가르키는 단어가 무엇인지 Self Attention을 이용해 알 수 있음
3.2 End-to-End memory Network
- 시퀀스가 배열된 recurrence보다 recurrent attention mechanism 기반
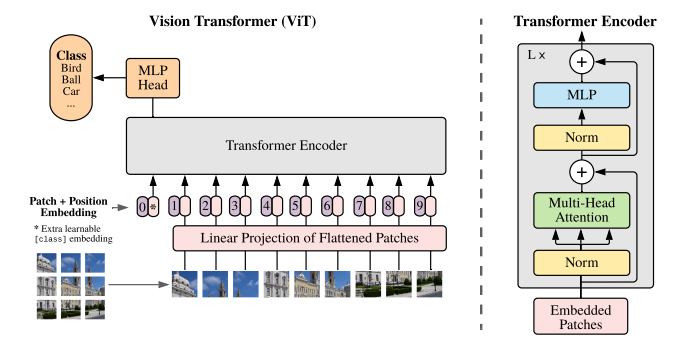
4. Model Architecture
- 기존의 Sequence 변환 모델은 아래와 같은 구조를 가지고 있음
- 이러한 구조는 항상 이전 단계가 완료되어야 다음 단계가 진행 가능 ⇒ 병렬 처리 불가능
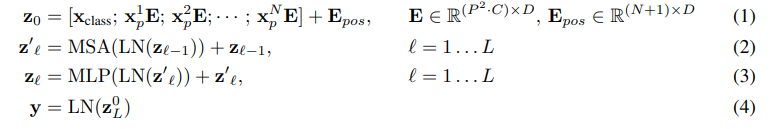
- Transformer는 인코더와 디코더 모두에서 스택된 Self Attention과 Point-wise 완전 연결층을 사용하는 아래의 사진과 같은 구조를 가짐
4.1 Encoder and Decoder Stacks
- Encorder : 6개(N=6)의 동일한 레이어로 이루어져 있으며 하나의 인코더는 Self-Attention layer와 Feed Forward Neural Network라는 두 개의 Sub layer로 이루어져 있음
- Decorder: 6개(N=6)의 동일한 레이어, 각 레이어는 인코더가 Sub layer로 가진 Self-Attention layer와 Feed Forward Neural Network 외에 Masked Multi-Head Attention layer를 가짐
4.2 Attention
4.2.1 Scaled Dot-Product Attention
Query : 영향을 받을 단어 (벡터)
Key : 영향을 주는 단어 (벡터)
Value : 영향에 대한 가중치 (벡터)
이 식을 이용해 계산
< 계산 과정 요약 >
(1) 워드 임베딩에 가중치(
- Query:
- Key:
- Value:
(2) Query * Key = attention score ⇒ 값이 높을 수록 연관성이 높고, 낮을 수록 연관성이 낮다.
(3) key 차원수로 나누고 softmax 적용 ⇒ softmax 결과 값은 key값에 해당하는 단어가 현재 단어에 어느정도 연관성이 있는지 나타냄
(4) 문장 속에서 지닌 입력 워드의 값 = softmax 값과 value 값을 곱하여 다 더함
4.2.2 Multi-Head Attention
- 문장을 다양한 관점에서 모델이 해석 가능하도록 하는 역할
Attention을 parallel하게 구성해서 여러번 계산하는 구조

- 위의 그림을 볼 때 it이 가르키는 단어가 무엇인지 확실히 알 수 없음
- 이때 Multi-Head Attention을 이용하면 알 수 있음
⇒ Head의 갯수를 (논문에서) 8개를 두고 모든 Head를 Scaled Dot-Product Attention을 진행
⇒ 다양한 관점에서 문장을 볼 수 있게 됨 - Single-Head Attention의 출력 채널이
이라고 할 때 Multi-Head Attention에서의 각 Head의 출력 채널은 차원을 가지게 됨 ⇒ 계산 비용은 Single과 Multi가 비슷하지만 Multi-Head를 사용하면 더 다양한 정보를 동시에 얻을 수 있게됨
4.2.3 Application in Attention in our Model
Transformer는 세 가지 다른 방식으로 Multi-Head Attention을 사용
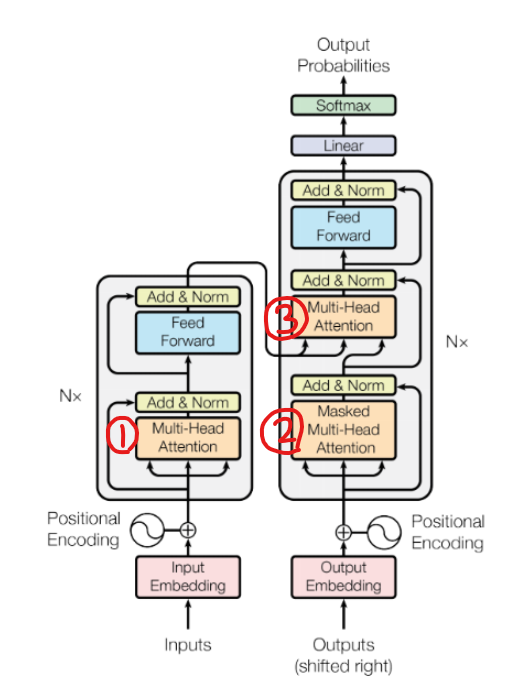
- "self-attention in encoder": encoder에서 사용되는 self-attention으로 queries, keys, values 모두 encoder로부터 가져온다. encoder의 각 position은 그 전 layer의 모든 positions들을 참조하고, 이는 해당 position과 모든 position간의 correlation information을 더해주게 된다. 간단하게 설명해서 어떤 한 단어이 모든 단어들 중 어떤 단어들과 correlation이 높고, 또 어떤 단어와는 낮은지를 배우게 된다.
- "self-attention in decoder": 전체적인 과정과 목표는 encoder의 self-attention과 같다. 하지만 decoder의 경우, sequence model의 auto-regressive property를 보존해야하기 때문에 masking vector를 사용하여 해당 position 이전의 벡터들만을 참조한다(이후에 나올 단어들을 참조하여 예측하는 것은 일종의 치팅).
- "encoder-decoder attention": decoder에서 self-attention 다음으로 사용되는 layer이다. queries는 이전 decoder layer에서 가져오고, keys와 values는 encoder의 output에서 가져온다. 이는 decoder의 모든 position의 vector들로 encoder의 모든 position 값들을 참조함으로써 decoder의 sequence vector들이 encoder의 sequence vector들과 어떠한 correlation을 가지는지를 학습한다.
4.3 Position-wise Feed-Forward Networks
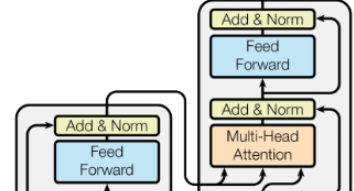
- Transformer에서 fully connected feed-forward network가 사용됨
- 2개의 선형 변환으로 구성되고 그 사이에 ReLU 활성화 함수가 존재
- 입출력 차원
이고 hidden 레이어의 차원은 를 가짐
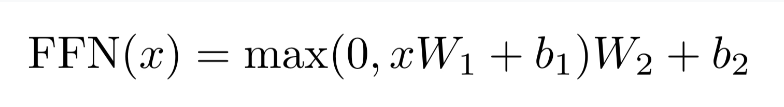
4.4 Embeddings and Softmax
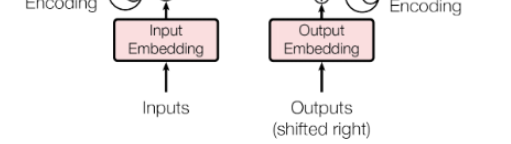
- input과 output 토큰을 embedding layer를 거쳐서 사용
- input embedding 과 output embedding에서 weight matrix를 서로 공유
4.5 Positional Encoding
Sequence의 순서를 활용하기 위해 토큰의 상대적 또는 절대적인 위치에 대한 정보를 제공
- Transformer에서는 Attention만 사용하기 때문에 위치 정보를 얻을 수 없음
- 따라서 이러한 위치 정보를 얻기 위해 “Positional Encoding”을 진행함
- 논문에서는 sin 함수와 cos 함수를 이용해 진행
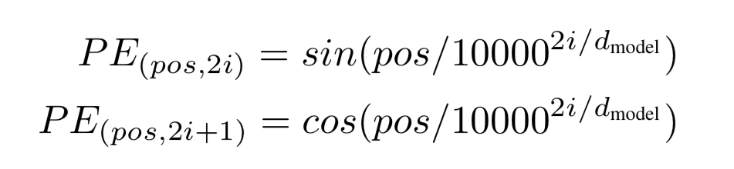
pos는 position, i는 dimension
5.Why Self-Attention
왜 Self-Attention이 RNN, CNN 보다 더 좋은가?
- Layer당 계산 복잡성이 줄어듦
아래의 표를 확인해보면 Self-Attention의 계산 복잡도가 다른 것에 비해 낮은 것을 알 수 있음

보통 sequence length n이 vector dimension d보다 작은 경우가 많다. Conv 크기 = k,
r은 모든 단어와 self attention이 아닌 일부 범위에서만 진행
-
병렬화 할 수 있는 계산량
Self-attention layer는 input의 모든 position 값들을 연결하여 한번에 처리할 수 있다. 따라서 Sequential operations이 O(1)을 가짐 ⇒ parallel system에서 유리하게 사용됨 -
장기 의존성 문제 해결
장기 의존성을 잘 배우기 위해서는 Length of paths가 큰 영향을 미침
length of paths 란 대응되는 input sequence token과 output sequence token 간의 거리
Maximum path length란 length of paths중에서 가장 긴 거리 ⇒ input의 첫 token과 output의 마지막 token (input sequence length + output sequence length)Self**-**attention은 각 token들을 모든 token들과 참조하여 그 correlation information을 구해서 더해주기 때문에(심지어 encoder-decoder끼리도), maximum path length를 O(1)이라고 볼 수 있다. 따라서 long-range dependencies를 더 쉽게 학습할 수 있다는 장점을 가진다.
6. Overall Training
Encoder에서는 문장 내 단어와 문맥을 이해하고, Decoder에서는 순차적으로 번역된 문장을 내놓는다.
(1) Encoding 과정:
예를 들어, "The cat sits"라는 문장이 있다고 가정해 봅시다. 이 문장이 Transformer 모델의 입력으로 들어가면, 각 단어는 벡터로 변환됩니다( → 임베딩). 동시에, 각 단어의 위치 정보도 벡터로 표현됩니다( →포지셔널 임베딩)
- "The" → [0.1, 0.5, ...] (임베딩 벡터)
- "cat" → [0.2, 0.3, ...] (임베딩 벡터)
- "sits" → [0.4, 0.7, ...] (임베딩 벡터)
이렇게 임베딩된 단어 시퀀스는 Self-Attention과 Feed-Forward Network를 포함하는 Encoder 블록을 통과합니다.
이 과정을 통해 문장의 각 단어는 자신이 어떤 의미를 가지며, 다른 단어들과 어떤 관계를 맺고 있는지를 표현하는 벡터로 인코딩됩니다.
예를 들어, "cat"이라는 단어가 "sits"와 밀접한 관계가 있다면, "cat" 벡터는 이 정보를 포함하게 됩니다.
(2) Decoding 과정:
이제 모델은 "The cat sits"라는 문장을 다른 언어로 번역하려고 합니다. 예를 들어, "The cat sits"를 한국어로 번역한다고 해봅시다.
Decoder는 번역된 문장을 생성합니다. 이 과정에서 단어들은 하나씩 순서대로 출력됩니다. 예를 들어, 처음에는 시작 토큰(start token)이 입력으로 들어가 "고양이"라는 단어가 가장 높은 확률로 출력됩니다.
- 첫 번째 입력: 시작 토큰 → 출력: "고양이"
그 다음에는 "고양이"라는 단어가 다시 디코더의 입력으로 사용되어, "는"이라는 단어가 출력됩니다.
- 두 번째 입력: "고양이" → 출력: "는"
마지막으로, "고양이"와 "는"이 함께 입력되어, "앉아있다"가 출력됩니다.
- 세 번째 입력: "고양이 + 는" → 출력: "앉아있다"
이 과정에서 Self-Attention 레이어는 해당 위치보다 이전에 생성된 모든 단어를 참조하여 올바른 번역을 생성할 수 있도록 합니다. 이때 현재 위치 이후의 단어는 매우 작은 값(보통
이렇게 하면 디코더는 아직 생성되지 않은 단어에 영향을 받지 않고, 이미 생성된 단어들만을 기반으로 번역을 이어갑니다.
또한 디코더는 Encoder-Decoder Attention 레이어를 통해, 인코더에서 나온 정보를 활용합니다. 예를 들어, 디코더의 각 단어는 인코더에서 생성된 "The cat sits"의 벡터들과 어텐션을 계산하여, 번역 과정에서 입력 문장의 모든 위치를 참조하게 됩니다.